掌握 Hive 索引的数据导入秘籍
Hive 索引在处理大规模数据时扮演着至关重要的角色,而在数据导入阶段,采取正确的策略更是能显著提升数据处理的效率和质量。
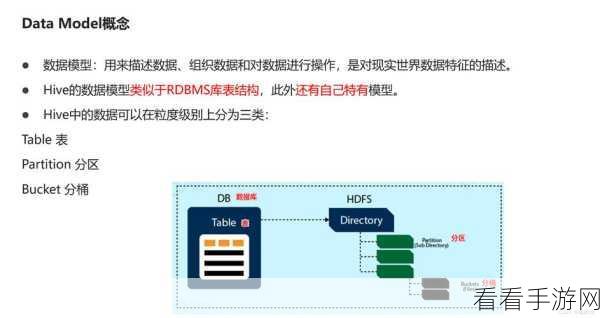
在数据导入时,了解 Hive 索引的特点和适用场景是关键,Hive 索引主要分为两类:聚集索引和非聚集索引,聚集索引基于表中的数据进行物理排序,能够加快查询速度;非聚集索引则类似于数据库中的普通索引,通过建立索引列与数据行的映射关系来提高查询效率。
要想制定有效的数据导入策略,必须充分考虑数据的特点和业务需求,对于频繁查询的列,建立索引能够显著提高查询性能,但需要注意的是,索引并非越多越好,过多的索引可能会导致数据插入和更新的性能下降。
在实际操作中,合理选择索引类型也是至关重要的,如果数据的分布比较均匀,聚集索引可能效果不明显,此时非聚集索引或许是更好的选择,反之,如果数据具有明显的聚集特征,聚集索引则能发挥更大的作用。
数据量的大小也会影响索引策略的制定,对于小型数据集,索引带来的性能提升可能并不明显;而对于大型数据集,精心设计的索引则能带来巨大的效益。
在数据导入过程中,还需要注意索引的维护和更新,随着数据的不断变化,及时更新索引可以确保其有效性。
掌握 Hive 索引在数据导入时的策略,需要综合考虑多种因素,结合实际情况进行灵活运用,才能实现数据处理的高效和优化。
参考来源:相关技术文档及实践经验总结。
