Stream Kafka 数据一致性的保障秘籍
在当今数字化时代,数据的一致性对于各种应用至关重要,特别是在像 Stream Kafka 这样的系统中,Stream Kafka 作为一种强大的数据处理工具,如何确保数据的一致性成为了开发者和运维人员关注的焦点。
Stream Kafka 保证数据一致性的关键在于其精心设计的机制,首先是消息的持久化存储,通过将消息写入可靠的存储介质,确保数据不会轻易丢失,其次是副本机制,多个副本的存在增加了数据的冗余度,即使某个节点出现故障,也能从其他副本中恢复数据,再者是消息的确认机制,只有当生产者收到确认信息,才表示消息成功发送,从而避免了数据的遗漏。
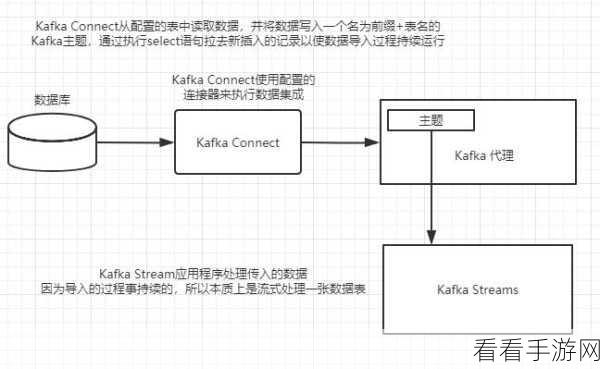
在数据处理过程中,Stream Kafka 还采用了分区和消费者组的方式,以实现更高效的数据分发和处理,分区使得数据能够并行处理,提高了系统的吞吐量;消费者组则保证了同一组内的消费者能够协同工作,避免重复处理数据。
Stream Kafka 对于错误处理也有着严格的策略,当出现网络故障、节点宕机等异常情况时,系统能够迅速进行故障检测和恢复,保证数据的一致性不受影响。

为了更好地理解和应用 Stream Kafka 保证数据一致性的方法,开发者和运维人员需要深入了解其内部机制,并结合实际业务场景进行优化配置,只有这样,才能充分发挥 Stream Kafka 的优势,为企业的业务发展提供稳定可靠的数据支持。
文章参考来源:相关技术文档及行业研究报告。
