探究 grpc 和 kafka 对高吞吐量的支撑能力
在当今数字化的时代,数据处理的需求日益增长,高吞吐量成为了许多系统和技术面临的重要挑战,grpc 和 kafka 这两项技术备受关注,它们能否支持高吞吐量成为了大家关心的焦点。
grpc 是一种高性能、开源的远程过程调用框架,具有高效的序列化和传输机制,其设计目标之一就是为了应对大规模的分布式系统中的通信需求,而 kafka 作为一个分布式的消息队列系统,以其出色的消息处理和分发能力而闻名。
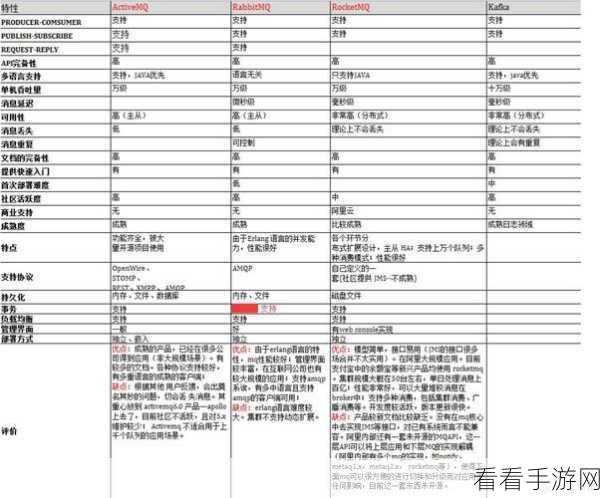
要评估 grpc 和 kafka 对高吞吐量的支持能力,我们需要从多个方面进行考量,首先是它们的架构设计,grpc 的架构强调了轻量级和高效的通信,通过使用 Protocol Buffers 进行序列化,减少了数据传输的开销,而 kafka 的分布式架构使得它能够横向扩展,处理大量的消息生产和消费。
性能测试和实际应用场景的表现,通过模拟高并发的请求和数据处理,观察 grpc 和 kafka 在不同负载下的响应时间、吞吐量和资源利用率等指标,实际应用中的成功案例也能为我们提供有力的参考,了解它们在真实业务环境中的表现。
配置优化也是关键因素,对于 grpc 和 kafka ,合理的配置参数设置可以显著提升其性能,调整缓冲区大小、消息分区策略、线程池大小等,以适应不同的业务需求和硬件环境。
社区支持和持续更新也对其支持高吞吐量的能力有着重要影响,活跃的社区能够及时解决问题、提供优化建议,并推动技术的不断发展和完善。
grpc 和 kafka 在支持高吞吐量方面具有一定的潜力,但需要综合考虑架构设计、性能测试、配置优化以及社区支持等多方面因素,只有在充分了解和合理运用的基础上,才能发挥它们的最大优势,满足日益增长的高吞吐量数据处理需求。
文章参考来源:相关技术文档和行业研究报告。
