探秘高级 Python 爬虫的分布式爬取秘籍
Python 爬虫技术在当今的网络数据获取中扮演着重要角色,而高级 Python 爬虫的分布式爬取更是一项极具挑战性和实用性的技能。
要理解高级 Python 爬虫的分布式爬取,我们得先清楚什么是分布式爬取,分布式爬取是指通过多个节点协同工作,共同完成大规模数据的抓取任务,它的优势在于能够大大提高爬取效率,缩短爬取时间,同时应对反爬虫机制也更有优势。
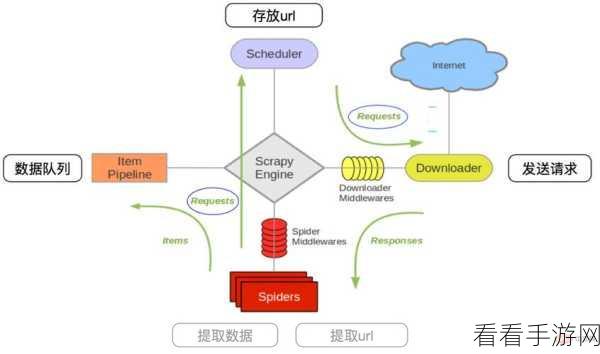
实现高级 Python 爬虫的分布式爬取,需要有合理的架构设计,常见的分布式架构包括主从模式和对等模式,主从模式中,有一个主节点负责任务分配和结果整合,从节点则专注于执行具体的爬取任务,对等模式下,各个节点地位平等,共同协作完成任务。
在分布式爬取中,任务的分配和调度至关重要,这需要精心设计的算法和策略,以确保每个节点都能得到合适的任务,避免重复劳动和资源浪费,还需要考虑节点之间的通信和数据同步问题,保证数据的一致性和完整性。

数据存储也是一个关键环节,由于分布式爬取会产生大量的数据,选择合适的数据库和存储方式非常重要,使用分布式数据库可以提高数据的存储和查询效率。
还需要注意法律法规和网站的使用规则,爬取数据必须在合法合规的前提下进行,不得侵犯他人的权益和违反相关规定。
掌握高级 Python 爬虫的分布式爬取技术,需要综合考虑架构设计、任务分配、数据存储等多个方面,同时遵守法律法规,才能充分发挥其优势,为我们获取有价值的数据提供有力支持。
文章参考来源:相关技术文档和专业书籍。
