探索 Hive 中 Split 的精妙实现之道
Hive 中的 Split 操作,对于数据处理和分析来说,是一项至关重要的技术。
Split 操作在 Hive 里具有独特的作用和意义,它能够将数据按照特定的规则和条件进行分割,从而为后续的处理和分析提供更灵活、更高效的数据结构。
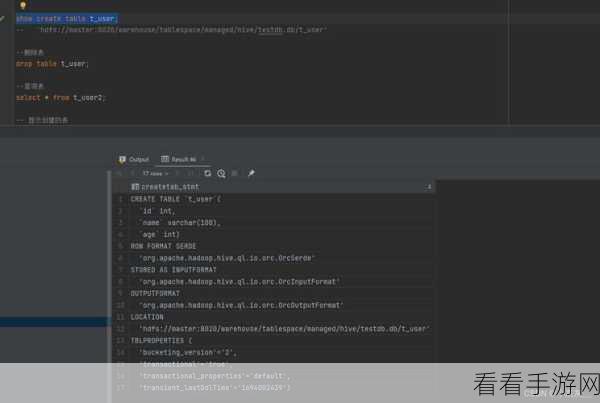
要实现 Hive 的 Split ,需要明确一些关键的要点,要对数据的特征和分布有清晰的了解,只有知道数据的特点,才能确定合适的分割方式和规则,要熟悉 Hive 中相关的函数和语法,通过特定的字符串处理函数或者正则表达式,来定义分割的依据,要考虑性能和效率的问题,在大规模数据处理中,不合理的 Split 方式可能导致性能下降,影响整个任务的执行速度。
在实际应用中,有许多场景会用到 Hive 的 Split ,比如在数据分析中,需要将复杂的数据按照不同的维度进行拆分,以便分别进行统计和分析,又比如在数据清洗阶段,将不符合规范的数据进行分割和处理。
为了更好地掌握 Hive 的 Split 实现,建议多进行实践和测试,可以通过创建不同规模和类型的数据集,尝试各种分割方式,观察其效果和性能,参考 Hive 的官方文档和相关的技术论坛,与其他开发者交流经验和心得,也能帮助我们不断提升对这一技术的理解和运用能力。
参考来源:Hive 官方文档及相关技术论坛交流
