Flink 与 Spark 终极对决,谁更胜一筹?
在当今大数据处理领域,Flink 和 Spark 都是备受瞩目的技术框架,关于它们谁更出色的讨论从未停歇。
Flink 以其出色的实时处理能力而闻名,它能够实现低延迟的数据处理,对于那些对数据实时性要求极高的场景,如金融交易监控、实时推荐系统等,Flink 往往能够提供更出色的表现。
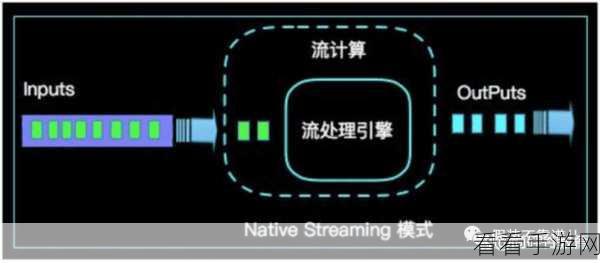
Spark 则在批处理方面有着深厚的积累和优势,它具备强大的容错能力和丰富的生态系统,对于大规模数据的批量处理任务,能够高效稳定地完成。
要评判 Flink 和 Spark 哪个更好,并不能简单地一概而论,这取决于具体的应用场景和需求。
如果您的业务注重实时性,需要快速响应和处理数据,Flink 可能是更合适的选择,它能够在毫秒级别内处理数据,确保您不会错过任何关键的信息。
但如果您面对的是大规模的历史数据处理,需要进行复杂的数据分析和挖掘,Spark 可能会更能满足您的需求,其丰富的库和工具能够帮助您轻松实现各种复杂的计算逻辑。
在资源利用方面,Flink 和 Spark 也有所不同,Flink 能够更有效地利用内存资源,而 Spark 在处理大规模数据时,对内存的需求相对较高。
Flink 和 Spark 各有千秋,在实际应用中,我们应根据具体的业务需求和技术环境来选择最适合的框架,以实现数据处理的最佳效果。
参考来源:相关技术论坛及官方文档。
希望以上内容对您有所帮助!
