揭秘 Spark 算法的数据处理极限
Spark 算法,作为大数据处理领域的重要工具,其数据处理能力一直备受关注,它究竟能处理多大规模的数据呢?这是众多数据从业者和研究者心中的疑问。
Spark 算法具有出色的并行计算能力,这使得它在处理大规模数据时表现优异,其核心优势在于能够将数据分布在多个节点上进行并行处理,从而大大提高了处理速度和效率。
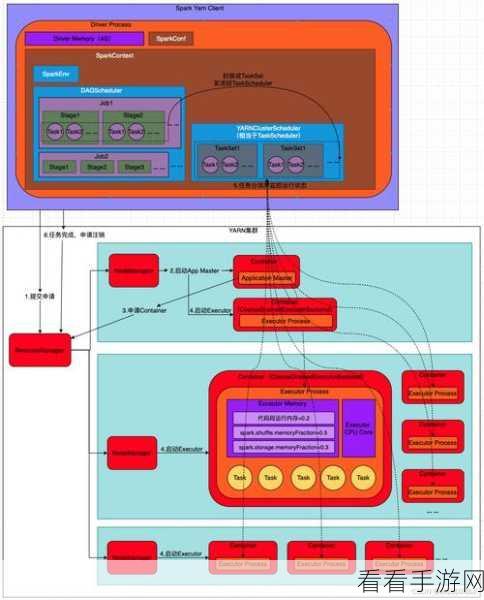
要评估 Spark 算法的数据处理能力,需要考虑多个因素,首先是硬件资源,包括服务器的配置、内存大小和网络带宽等,充足的硬件资源能够为 Spark 算法提供有力的支持,使其能够处理更大量的数据,其次是数据的特点,例如数据的类型、结构和分布情况,不同类型和结构的数据对处理能力的要求也有所不同,算法的优化和调整也是影响处理能力的关键因素,通过合理的参数设置和算法优化,可以进一步提升 Spark 算法的性能。
在实际应用中,许多企业和机构已经成功运用 Spark 算法处理了海量的数据,某大型电商平台利用 Spark 算法对用户的购买行为数据进行分析,实现了精准的推荐服务;某金融机构则借助 Spark 算法对交易数据进行风险评估,有效地防范了金融风险。
为了充分发挥 Spark 算法的数据处理能力,我们需要不断地探索和创新,要持续优化硬件设施,提供更强大的计算和存储能力;要深入研究算法的优化策略,结合具体的业务需求进行定制化的开发。
Spark 算法的数据处理能力具有巨大的潜力,但要实现其最佳效果,需要综合考虑多方面的因素,并不断进行优化和改进。
文章参考来源:相关大数据处理技术研究资料。
