Hive 分位数函数优化秘籍大揭秘
在当今的数据处理领域,Hive 分位数函数的优化至关重要,它不仅影响着数据处理的效率,还决定着数据分析结果的准确性。
Hive 分位数函数在实际应用中常常面临诸多挑战,数据量过大时计算速度缓慢,或者在复杂数据结构下准确性难以保证,如何对 Hive 分位数函数进行有效的优化呢?

要优化 Hive 分位数函数,第一步需要深入理解其工作原理,只有清晰地知晓函数是如何对数据进行处理和计算的,才能找到优化的切入点。
合理调整参数是关键,不同的参数设置会直接影响函数的性能,通过对参数的精细调整,可以在一定程度上提升计算速度和准确性。
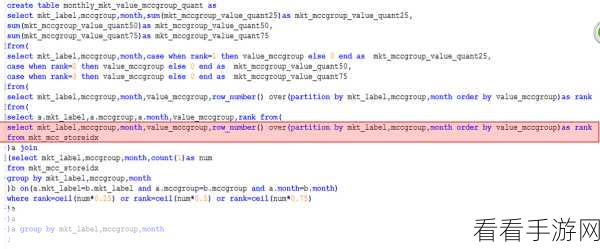
还可以考虑结合其他相关技术和工具,利用缓存机制来减少重复计算,或者借助分布式计算框架来并行处理数据,从而提高整体的效率。
在优化过程中,要注重数据的预处理,对原始数据进行清洗、筛选和整理,能够为分位数函数的计算提供更优质的输入,进而提升其性能。
不断进行测试和评估也是必不可少的,通过实际的测试案例,对比优化前后的效果,及时发现问题并进行调整,以确保优化方案的有效性。
优化 Hive 分位数函数需要综合考虑多个方面,从原理理解到参数调整,从技术结合到数据预处理,再到持续的测试评估,每一个环节都至关重要,只有这样,才能真正实现 Hive 分位数函数的高效优化,为数据处理和分析工作带来更大的价值。
文章参考来源:个人在 Hive 分位数函数优化方面的实践经验总结。
