Hive 和 Spark 作为大数据处理领域的重要工具,它们的性能对比一直备受关注,在实际应用中,了解它们的性能差异对于优化数据处理流程至关重要。
Hive 是基于 Hadoop 的数据仓库工具,具有稳定可靠的特点,它擅长处理大规模的结构化数据,对于复杂的查询和批处理任务有着出色的表现,Hive 在处理速度上可能相对较慢,特别是对于实时性要求较高的场景,可能无法满足需求。
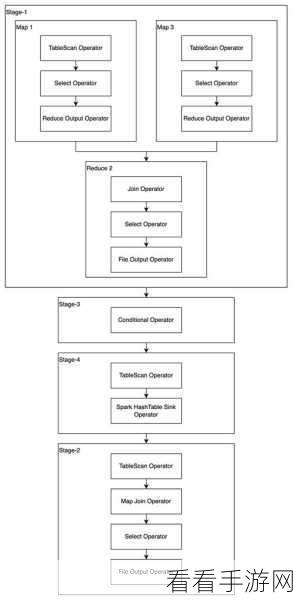
Spark 则是一种快速、通用的大数据处理框架,它提供了内存计算的能力,大大提高了数据处理的速度,Spark 对于迭代计算和流处理具有明显的优势,能够更高效地处理实时数据和复杂的数据分析任务。
如何评估 Hive 和 Spark 的性能呢?首先需要考虑数据量的大小,在处理小数据量时,Spark 的优势可能并不明显;但随着数据量的增加,Spark 的性能提升会更加显著,任务的类型也是影响性能的重要因素,对于简单的查询,Hive 可能表现不错;而对于复杂的机器学习和数据分析任务,Spark 通常更具优势。
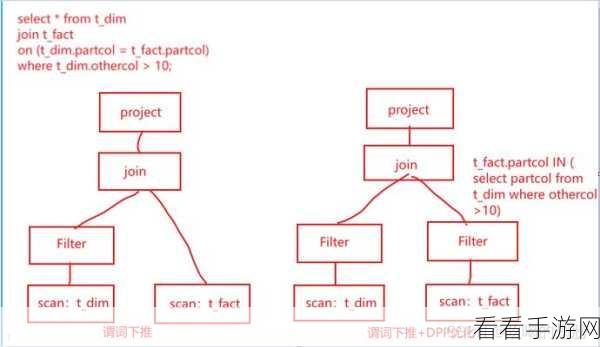
资源配置也会对性能产生影响,合理分配计算资源、内存和存储,可以优化 Hive 和 Spark 的性能,数据的分布和存储方式也会在一定程度上决定它们的处理效率。
Hive 和 Spark 各有优劣,具体的性能表现取决于多种因素,在实际应用中,需要根据具体的业务需求和场景来选择合适的工具,以达到最佳的数据处理效果。
参考来源:相关大数据技术研究资料及实际应用案例。