Python BeautifulSoup 爬虫调试的可能性与技巧
Python 的 BeautifulSoup 爬虫技术在数据获取和处理方面具有显著的优势,但很多开发者会有疑问,它能否进行调试呢?答案是肯定的。
调试对于爬虫开发至关重要,通过调试,可以及时发现并解决代码中的错误,提高爬虫的稳定性和准确性。
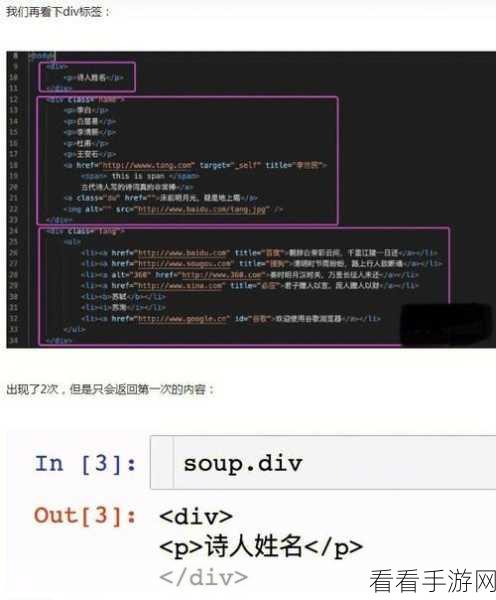
要成功调试 Python BeautifulSoup 爬虫,首先需要了解常见的错误类型,比如语法错误、逻辑错误和运行时错误等,语法错误通常在编写代码时就能被编译器检测出来,相对容易发现和修正,而逻辑错误和运行时错误则需要通过仔细分析代码和运行结果来排查。
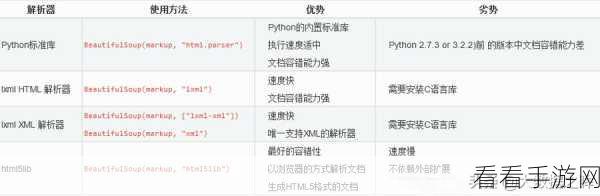
合理使用调试工具是关键,Python 提供了多种调试工具,如 print 语句、pdb 调试器等,print 语句可以输出关键变量的值和中间结果,帮助我们了解代码的执行情况,pdb 调试器则提供了更强大的调试功能,如设置断点、单步执行、查看变量值等。
对于 BeautifulSoup 还需要注意网页结构的变化,因为网页的结构可能会不定期更新,如果爬虫代码依赖于固定的网页结构,就很容易出现错误,所以在开发过程中,要考虑网页结构变化的可能性,并编写相应的处理代码。
不断测试和优化也是必不可少的,在完成初步的调试后,要对爬虫进行充分的测试,确保其在不同的网页和环境下都能正常工作,根据测试结果对代码进行优化,提高爬虫的性能和效率。
掌握 Python BeautifulSoup 爬虫的调试方法和技巧,能够让开发者更加高效地开发出稳定可靠的爬虫程序,为数据获取和分析提供有力支持。
参考来源:相关 Python 技术文档及开发经验总结
