深度解析,Apache Kafka 消息回溯的关键技巧
Apache Kafka 作为一款强大的分布式消息系统,其消息回溯功能在众多应用场景中发挥着重要作用。
想要实现 Apache Kafka 的消息回溯,首先要了解其基本原理,Kafka 通过分区和偏移量来管理消息的存储和读取,每个分区中的消息都有对应的偏移量,通过控制偏移量就能实现消息的回溯。
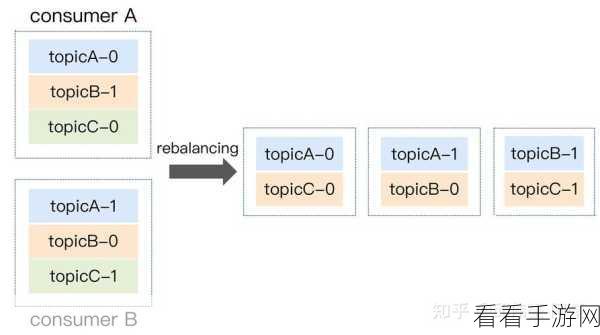
在实际操作中,Kafka 提供了多种方式来进行消息回溯,可以使用特定的 API 来调整消费者的偏移量,从而达到回溯消息的目的,还可以利用 Kafka 的配置参数,对消息的保留时间和存储策略进行设置,为消息回溯提供更多的可能性。
要注意在进行消息回溯时可能会遇到的一些问题,回溯的范围过大可能会导致系统性能下降,或者回溯过程中出现数据不一致的情况,在进行消息回溯前,需要对系统的负载和数据情况进行充分的评估和准备。
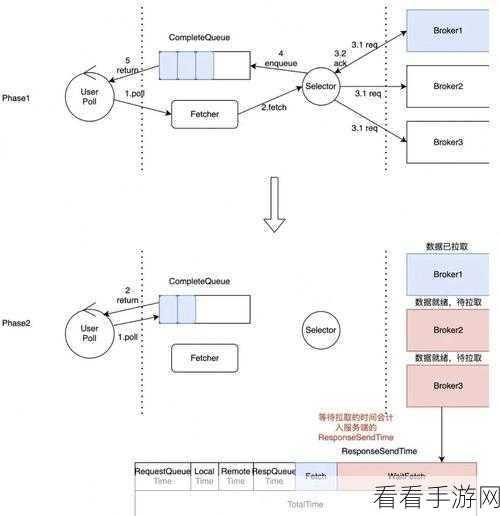
熟练掌握 Apache Kafka 的消息回溯技巧,需要对其原理有深入的理解,同时结合实际的应用场景和需求,选择合适的方法和策略,以确保系统的稳定和高效运行。
参考来源:相关技术文档及实践经验总结。
