Flink 与 Spark,能否实现完美替代的深度剖析
在当今大数据处理领域,Flink 和 Spark 是备受瞩目的两个技术框架,它们都在数据处理方面展现出强大的能力,但能否相互替代一直是众多开发者和技术人员争论不休的话题。
Flink 作为新兴的流处理框架,具有出色的实时处理性能和低延迟特性,它能够在处理海量数据时保持高效,并提供了精确的事件时间处理机制,这使得在对时效性要求极高的场景中,Flink 具有显著的优势。
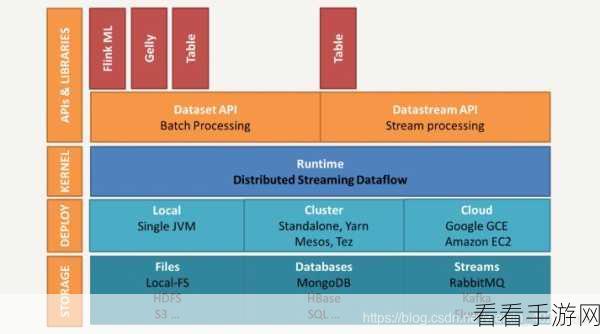
Spark 则是一款成熟且广泛应用的大数据处理框架,其批处理能力尤为出色,它在处理大规模数据时表现稳定,同时还具备丰富的生态系统和强大的机器学习支持。
要判断 Flink 和 Spark 是否能相互替代,不能仅仅从单一的性能指标或功能特性来考量,还需要综合考虑实际应用场景、团队技术栈以及项目需求等多方面因素。
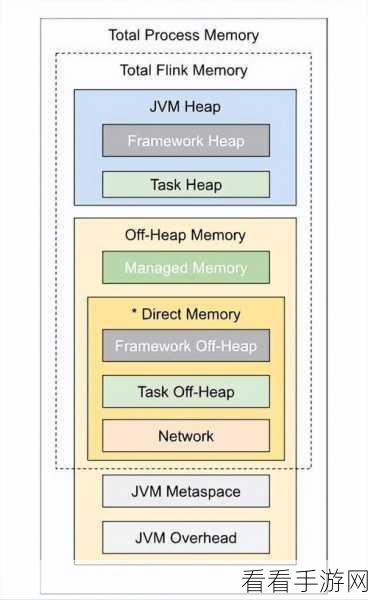
在一些实时性要求苛刻的业务场景,如金融交易实时监控、物联网数据实时分析等,Flink 往往能够更好地满足需求,但对于大规模数据的批处理和复杂的机器学习任务,Spark 可能更具优势。
团队的技术积累和人员熟悉程度也是影响选择的重要因素,如果团队已经对 Spark 有深入的了解和丰富的实践经验,那么在新项目中继续使用 Spark 可能会降低技术风险和开发成本。
Flink 和 Spark 各有其独特之处,不能简单地认为它们可以相互替代,在实际应用中,应根据具体的业务需求和技术环境,合理选择和运用这两个框架,以实现最佳的数据处理效果。
参考来源:大数据技术相关研究文献及技术社区讨论。
仅供参考,您可以根据实际需求进行调整。
