深度剖析,Hive 与 Spark 数据同步的疑难杂症
在当今数字化时代,数据处理成为了企业和组织发展的关键环节,Hive 和 Spark 作为常用的数据处理工具,它们之间的数据同步问题备受关注,本文将深入探讨这一难题,为您提供全面的解决方案。
中心句:数据处理在当今数字化时代至关重要,Hive 和 Spark 数据同步问题引人关注。
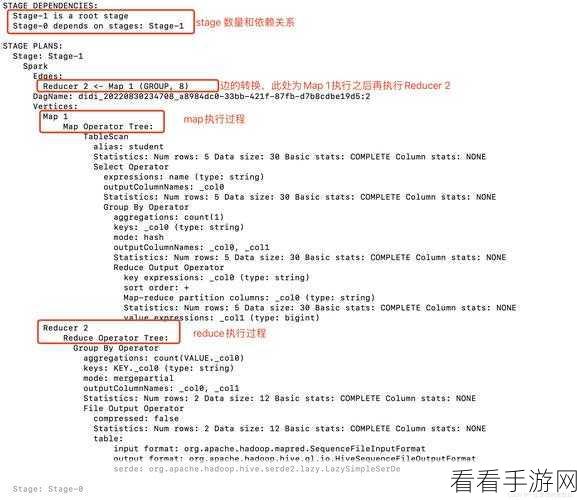
Hive 与 Spark 是大数据领域中广泛应用的技术,在实际应用中,它们的数据同步并非一帆风顺,数据类型的差异、存储格式的不同以及网络延迟等因素,都可能导致数据同步出现错误或延迟。
中心句:Hive 与 Spark 在实际应用中数据同步面临诸多挑战。
为了解决 Hive 和 Spark 的数据同步问题,我们需要从多个方面入手,要确保数据的一致性,这意味着在数据的输入、处理和输出阶段,都要进行严格的校验和验证,优化数据传输的方式和效率,选择合适的网络协议、压缩算法等,可以有效减少数据传输的时间和成本,合理配置系统资源也是关键,根据数据量和处理需求,合理分配内存、CPU 等资源,能够提高系统的整体性能。
中心句:解决 Hive 和 Spark 数据同步问题需多方面着手,包括确保数据一致性、优化传输方式和配置系统资源。
在实际操作中,我们还可以借助一些工具和技术来辅助解决数据同步问题,使用数据同步框架,如 Apache NiFi 等,可以简化数据同步的流程和配置,对数据进行分区和索引,能够提高数据的查询和同步效率。
中心句:实际操作中可借助工具和技术辅助解决数据同步问题,如使用数据同步框架及进行数据分区和索引。
Hive 和 Spark 的数据同步问题虽然复杂,但只要我们深入了解其原理,采取有效的解决措施,就能够实现高效、准确的数据同步,为企业和组织的发展提供有力支持。
中心句:Hive 和 Spark 数据同步问题虽复杂,但了解原理并采取措施可实现高效准确同步,为发展提供支持。
本文参考了大数据处理领域的相关研究和实践经验,旨在为读者提供有价值的参考。
