掌握关键技巧!Flink 集成 Hive 处理数据倾斜全攻略
在大数据处理领域,Flink 与 Hive 的集成应用越来越广泛,数据倾斜问题常常成为困扰开发者的难题,本文将为您深入剖析 Flink 集成 Hive 时数据倾斜的处理方法,助您轻松应对这一挑战。
数据倾斜是指在数据处理过程中,某些任务或节点处理的数据量远远大于其他任务或节点,导致系统性能下降,甚至出现任务失败的情况,在 Flink 集成 Hive 时,数据倾斜可能出现在多个环节。
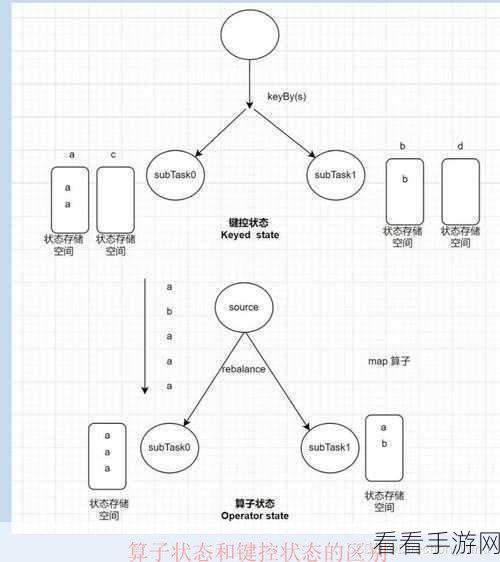
造成 Flink 集成 Hive 数据倾斜的原因多种多样,首先是数据分布不均匀,例如某些键值的出现频率过高,不同的数据类型处理方式差异也可能引发倾斜,任务的并行度设置不合理同样会导致这一问题。
针对数据倾斜问题,我们可以采取一系列有效的解决措施。
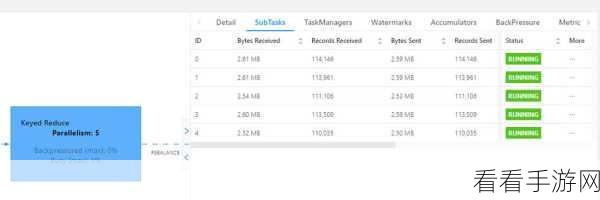
优化数据分布是一个重要的方法,通过对数据进行预处理,例如重新分区、加盐等操作,使得数据分布更加均匀,从而减轻数据倾斜的影响。
调整任务并行度也是关键的一步,根据数据量和计算资源,合理设置并行度,确保各个任务能够均衡地分配工作负载。
使用合适的聚合函数和窗口操作能够有效避免数据倾斜,选择具有更好性能和处理倾斜数据能力的聚合函数。
在实际应用中,我们需要结合具体的业务场景和数据特点,灵活运用这些方法,以达到最佳的处理效果,不断的测试和优化也是必不可少的,只有这样才能确保系统的稳定性和高效性。
参考来源:大数据处理相关技术文档及实践经验总结
