深入探究,Hive Hash 与数据类型的适配之谜
Hive Hash 是大数据处理中一个重要的概念,其在数据类型的适配方面有着诸多讲究。
Hive Hash 对于不同数据类型的适用性差异显著,首先要明确的是,基本数据类型如整数、浮点数和字符串,在 Hive Hash 中都有相应的处理方式,整数类型在 Hive Hash 中能够高效地进行存储和运算,因为其占用的存储空间相对较小,计算速度也较快,浮点数在某些特定场景下可能会存在精度损失的问题,但在一般的数据分析中,Hive Hash 也能对其进行合理的处理,字符串类型则需要根据具体的长度和内容来评估其在 Hive Hash 中的性能表现。
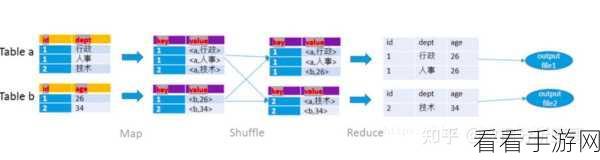
复杂数据类型如数组、结构体和映射等,在与 Hive Hash 结合时则需要更加谨慎地考虑,数组类型在 Hive Hash 中的处理相对复杂,需要注意数组元素的数量和类型一致性,结构体类型的适用性取决于其内部字段的类型和结构,若结构复杂,可能会影响 Hive Hash 的性能,映射类型在 Hive Hash 中的应用需要特别关注键值对的分布和唯一性。
数据的规模和分布也会对 Hive Hash 与数据类型的适配产生影响,当数据量庞大且分布不均匀时,选择合适的数据类型来配合 Hive Hash 就显得尤为重要,如果数据集中存在大量重复的字符串值,那么可能需要考虑采用更高效的编码方式来存储和处理。

了解 Hive Hash 适用于哪些数据类型,需要综合考虑数据类型的特点、数据的规模和分布等多方面因素,只有在充分了解这些因素的基础上,才能做出明智的选择,从而提高数据处理的效率和准确性。
文章参考来源:大数据处理相关技术文档及实践经验总结。
