Kafka 消息幂等,能否应对海量消息洪流?
Kafka 消息幂等性是一个备受关注的技术话题,尤其是在处理大量消息的场景中,它到底有没有能力应对如此繁重的任务呢?
Kafka 作为一种分布式消息队列,其在消息处理方面的表现备受赞誉,而消息幂等性则是确保消息在处理过程中不被重复处理的重要特性。
要探究 Kafka 消息幂等能否处理大量消息,我们首先需要了解什么是消息幂等,消息幂等就是指多次接收同一条消息并处理,其结果与只接收一次处理的结果是相同的,这在避免重复处理导致的数据不一致等问题上具有重要意义。
在实际应用中,Kafka 消息幂等的实现方式通常涉及到对消息的标识和去重处理,通过为每条消息赋予唯一的标识,在接收和处理时进行判断,从而确保不会对重复的消息进行重复处理。
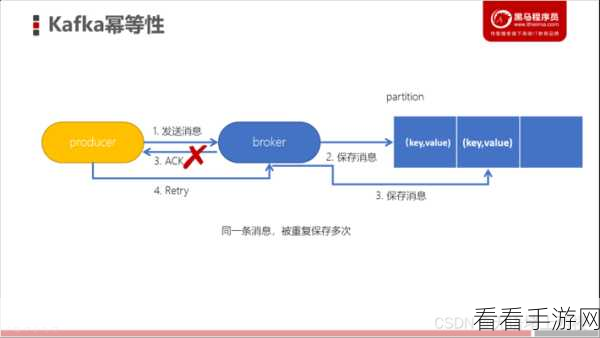
处理大量消息对于 Kafka 消息幂等来说并非毫无挑战,大量消息的涌入可能会给系统的性能带来压力,包括存储、计算和网络资源的消耗,复杂的业务逻辑可能会增加幂等处理的难度和复杂度。
为了应对这些挑战,优化系统配置和算法设计至关重要,合理调整 Kafka 的参数,如分区数量、副本数量等,可以提高系统的处理能力和容错性,精心设计幂等处理的算法,提高去重效率,也能有效提升系统在处理大量消息时的表现。
Kafka 消息幂等在理论上具备处理大量消息的能力,但在实际应用中,需要综合考虑各种因素,并进行针对性的优化和调整,以确保系统能够稳定高效地运行。
文章参考来源:相关技术文档和行业研究报告。
