Stream Kafka 数据聚合秘籍,实战技巧与策略解析
在当今的大数据时代,Stream Kafka 的数据聚合成为众多开发者关注的焦点,它不仅能够提升数据处理的效率,还能为业务决策提供有力支持。
Stream Kafka 数据聚合并非易事,需要我们深入理解其原理和掌握相应的技巧,要明确数据聚合的目标,是为了提取关键信息,还是为了进行数据压缩以节省存储空间?不同的目标会影响后续的操作策略。
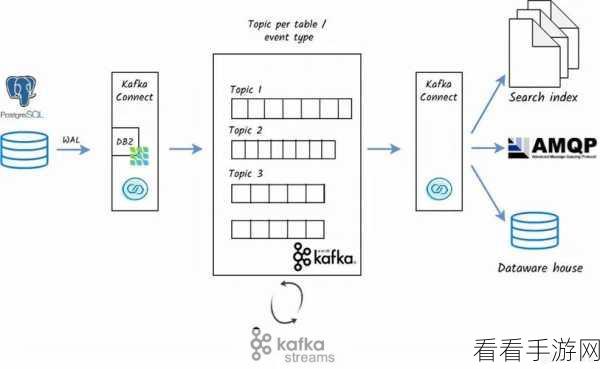
合理设置分区是关键,根据数据的特点和流量分布,将数据划分到合适的分区中,能够提高数据聚合的效率和准确性。
选择合适的聚合函数至关重要,常见的聚合函数如求和、平均值、计数等,要根据具体的业务需求来选用。
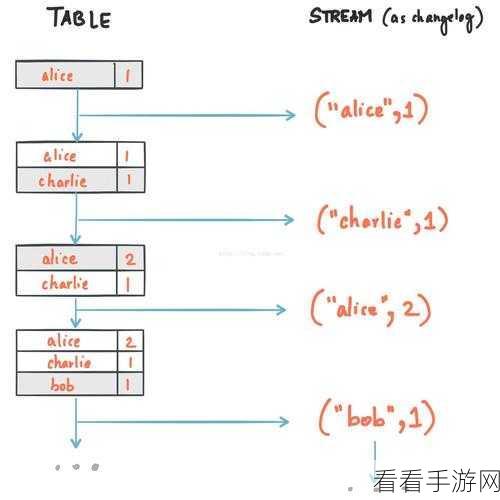
注意数据的时效性也是不可忽视的一点,及时处理和聚合最新的数据,能够确保分析结果的及时性和有效性。
在实际操作中,还需要不断进行测试和优化,通过监控性能指标,如数据处理的速度、资源的使用情况等,发现问题并及时调整策略。
Stream Kafka 的数据聚合是一个复杂但又极具价值的任务,只有掌握了正确的方法和技巧,才能充分发挥其优势,为业务发展提供强大的数据支持。
参考来源:行业经验与相关技术文档整理。
