探究 Kafka 消息幂等对处理速度的影响
Kafka 消息幂等是提升处理效率的关键吗?在当今数字化的时代,数据处理的速度和准确性至关重要,而 Kafka 作为一种流行的分布式消息系统,其消息幂等性备受关注。
Kafka 消息幂等旨在确保消息在处理过程中不会被重复处理,从而保障数据的一致性和准确性,它真的能够显著提高处理速度吗?
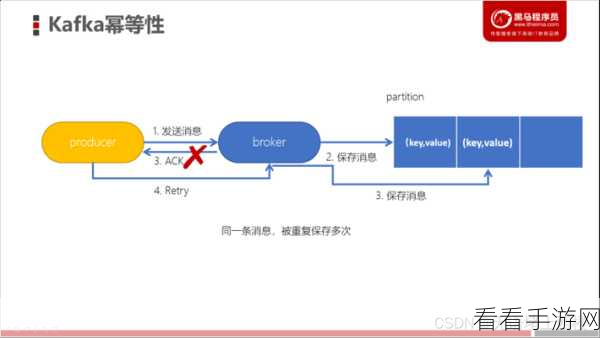
要深入理解这一问题,我们需要先明确 Kafka 消息幂等的工作原理,它通过识别和过滤重复的消息,避免了不必要的重复处理,这种机制在理论上能够减少系统的资源消耗,提高处理效率。
实际情况并非总是如此理想,消息幂等的实现需要一定的额外开销,例如消息标识的生成和存储,以及重复消息的检测和过滤过程,这些操作本身也会消耗一定的计算资源和时间。
Kafka 消息幂等的效果还受到多种因素的影响,比如消息的产生频率、处理逻辑的复杂性以及系统的整体架构等,在高并发的场景下,消息幂等可能会面临较大的压力,从而对处理速度产生一定的负面影响。
Kafka 消息幂等并非一定能够提高处理速度,其效果取决于多种因素的综合作用,在实际应用中,需要根据具体的业务需求和系统特点,谨慎评估和选择是否启用消息幂等功能,以达到最优的处理效果。
文章参考来源:相关技术文档和行业研究报告。
