Python BeautifulSoup 爬虫,强大还是鸡肋?
Python 的 BeautifulSoup 爬虫在数据获取领域一直备受关注,它究竟好不好用呢?这是许多开发者心中的疑问。
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库,其强大之处在于能够轻松处理各种复杂的网页结构,并提取出所需的信息。
使用 BeautifulSoup 爬虫也并非毫无挑战,对于一些动态生成的页面或者具有复杂反爬虫机制的网站,它可能会显得力不从心。
在处理大规模数据时,BeautifulSoup 的性能可能不如一些专门的爬虫框架,但对于小型项目和简单的网页抓取任务,它的便捷性和易用性使其成为不少开发者的首选。
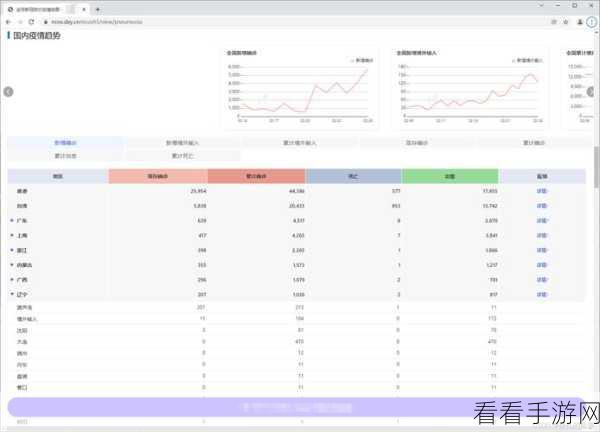
要想充分发挥 BeautifulSoup 爬虫的优势,开发者需要熟练掌握其各种方法和属性,并结合正则表达式等技术来提高数据提取的准确性和效率。
Python 的 BeautifulSoup 爬虫具有自身的特点和适用场景,在选择是否使用它时,应根据具体的项目需求和技术能力来综合考虑。
文章参考来源:相关技术论坛及官方文档。
