探秘,Nats Kafka 的高吞吐量性能究竟如何?
Nats Kafka 在当今的技术领域中备受关注,其能否支持高吞吐量是众多开发者和使用者关心的重要问题。
要深入了解 Nats Kafka 的高吞吐量性能,我们首先需要明确什么是高吞吐量,高吞吐量意味着在单位时间内能够处理大量的数据或请求。
Nats Kafka 之所以被探讨是否能支持高吞吐量,是因为在实际应用场景中,数据量的爆发式增长对系统的处理能力提出了极高要求,比如在大规模的实时数据处理、金融交易系统、物联网数据采集等领域,如果不能实现高吞吐量,可能会导致系统延迟、数据丢失等严重问题。
Nats Kafka 具备哪些特性有助于实现高吞吐量呢?其分布式架构是关键因素之一,通过将数据分布在多个节点上进行处理和存储,大大提高了系统的并行处理能力。
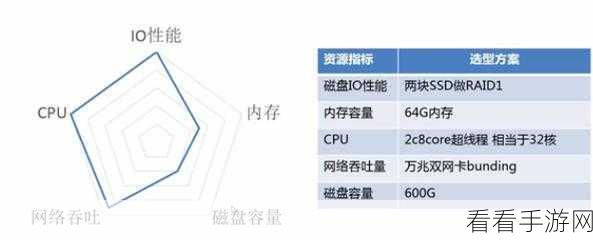
Nats Kafka 的优化的存储机制也为高吞吐量提供了支持,它能够有效地管理数据的存储和读取,减少磁盘 I/O 操作的时间消耗。
要充分发挥 Nats Kafka 的高吞吐量性能,还需要合理的配置和优化,调整缓冲区大小、优化网络参数等。
Nats Kafka 在理论上具备支持高吞吐量的潜力,但实际效果还需要根据具体的应用场景和配置进行评估和优化。
文章参考来源:相关技术文档及行业研究报告。
