探究 Kafka 的 ACK 对效率的关键影响
Kafka 的 ACK 机制在数据处理和传输中扮演着重要角色,直接关系到系统的效率和稳定性。
ACK 机制的设置决定了消息的确认方式,从而影响数据的可靠性和处理速度,当 ACK 级别较低时,虽然能提高消息的发送速度,但可能会增加数据丢失的风险;而较高的 ACK 级别则能确保数据的可靠传递,但会在一定程度上降低处理效率。
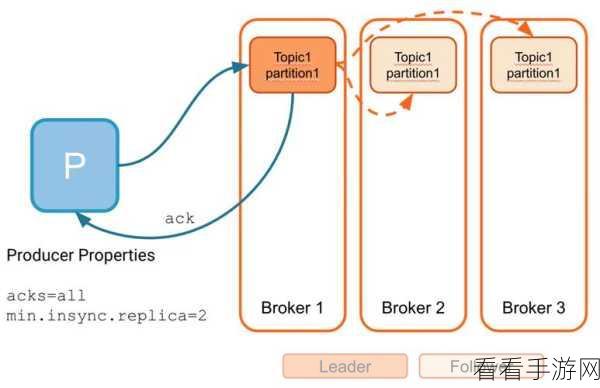
在实际应用中,需要根据具体的业务需求和场景来合理配置 ACK 选项,对于对数据准确性要求极高的金融交易场景,通常会选择较高的 ACK 级别,以确保每一条关键信息都能准确无误地传递和处理,而对于一些实时性要求较高,但对数据丢失有一定容忍度的场景,如实时的日志采集和分析,可能会采用较低的 ACK 级别来提高系统的整体处理速度。
还需要考虑系统的资源状况和负载情况,如果系统资源充足,能够承受较高 ACK 级别带来的额外开销,那么为了保证数据的可靠性,选择较高级别是明智之举,反之,如果系统资源紧张,或者需要处理的消息量巨大,可能需要在可靠性和效率之间进行权衡,找到一个最适合当前场景的 ACK 配置。
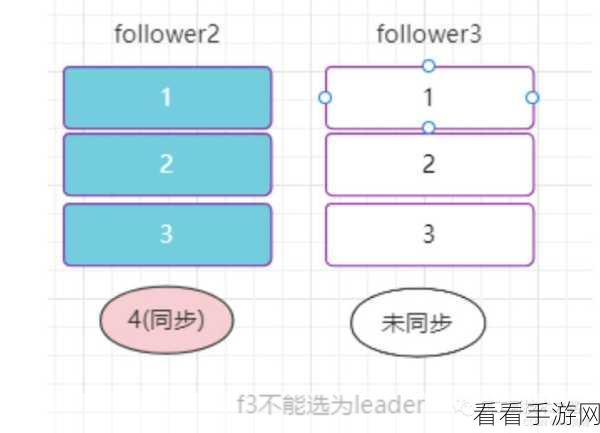
深入理解和合理运用 Kafka 的 ACK 机制,对于优化系统性能、提升数据处理效率以及保障数据的可靠性都具有重要意义。
参考来源:相关技术文档及行业研究报告。
