探索 syslog kafka 精准无误的奥秘
在当今数字化的时代,数据的准确传递和处理变得至关重要,而 syslog kafka 在这其中扮演着重要的角色,如何确保其准确性成为了众多开发者和运维人员关注的焦点。
想要实现 syslog kafka 的准确无误,关键在于对数据源头的严格把控,数据的产生环节必须遵循规范和标准,只有这样,才能为后续的处理和传递提供坚实的基础。

数据传输过程中的稳定性和可靠性也不容忽视,采用高效的网络架构和传输协议,能够减少数据丢失和延迟,从而保障数据的完整性和及时性。
对数据的验证和纠错机制是确保准确性的重要手段,通过设定一系列的规则和算法,对传入的数据进行实时校验,一旦发现错误能够及时纠正。
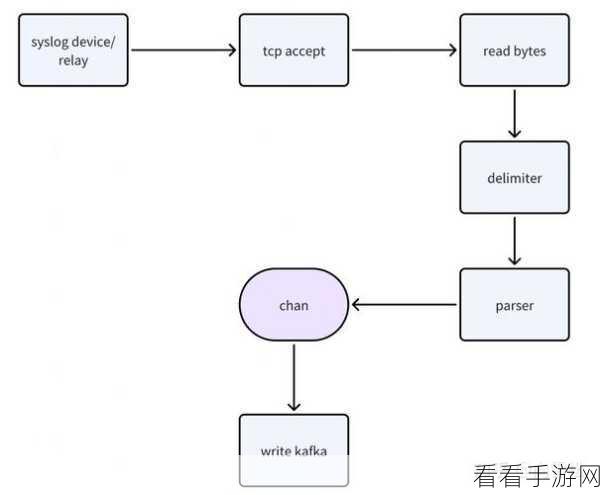
系统的监控和预警也是必不可少的环节,实时监测 syslog kafka 的运行状态,一旦出现异常能够迅速发出警报,让相关人员及时采取措施进行处理。
在实际应用中,不同的场景和需求可能会对 syslog kafka 的准确性提出不同的挑战,这就需要我们根据具体情况,灵活运用各种技术和策略,不断优化和改进,以达到最佳的准确性效果。
确保 syslog kafka 的准确并非一蹴而就,需要从多个方面进行综合考虑和精细管理。
参考来源:相关技术文档和行业经验总结。
仅供参考,您可以根据实际需求进行调整和修改。
