解锁 Flink 和 Kafka 优化配置的秘籍
在当今数字化时代,数据处理和传输的效率至关重要,Flink 和 Kafka 作为强大的工具,其配置优化成为众多开发者关注的焦点。
Flink 和 Kafka 是大数据处理领域中常用的技术框架,它们的有效结合能够实现高效的数据处理和流转,要想充分发挥它们的性能,优化配置是关键。
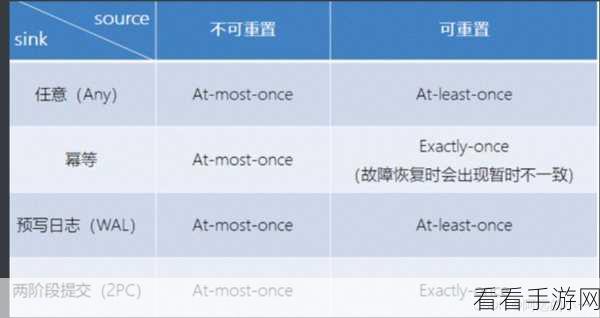
如何实现 Flink 和 Kafka 的优化配置呢?需要对 Flink 的任务并行度进行合理设置,任务并行度决定了 Flink 处理数据的并发能力,过高或过低都会影响性能,要根据数据量、计算复杂度以及硬件资源来综合考虑,Kafka 的分区数量也需要精心规划,分区数量过多可能导致资源浪费,过少则可能造成数据分布不均衡,应根据数据的产生速率和消费需求来确定合适的分区数,Flink 和 Kafka 之间的连接参数也不容忽视,设置合适的缓冲区大小、批量处理参数等,都能够提升数据传输的效率。
在实际应用中,还需要根据具体的业务场景和性能需求进行针对性的调整,不断地测试和优化,才能找到最适合的配置方案。
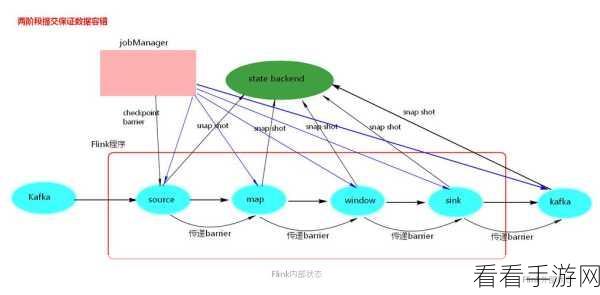
参考来源:大数据处理相关技术文档及实践经验。
希望以上内容能为您在 Flink 和 Kafka 优化配置方面提供有益的指导和帮助,让您的数据处理工作更加高效和顺畅。
