探秘 Kafka 顺序消息的实现秘诀
Kafka 作为一种强大的消息队列系统,其顺序消息的实现方式备受关注,在分布式系统中,保证消息的顺序性是一项具有挑战性的任务,而 Kafka 提供了有效的解决方案。
Kafka 实现顺序消息主要依靠分区机制,每个分区内的消息都按照发送的顺序进行存储和消费,这意味着,对于需要保证顺序的消息,将它们发送到同一个分区就能确保顺序性。
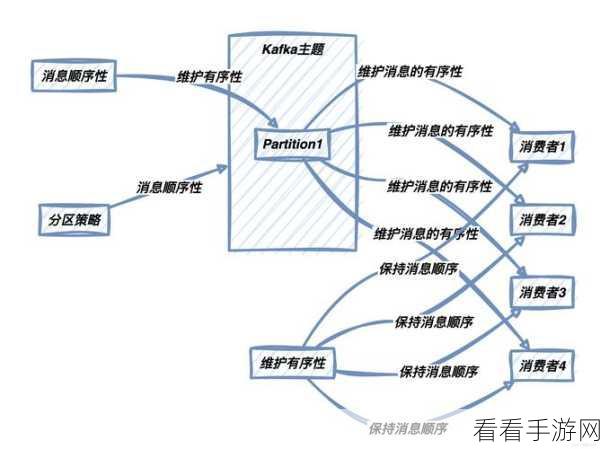
为了更好地理解 Kafka 顺序消息的实现,我们需要深入了解其存储结构,Kafka 将消息存储在分区的日志文件中,每个消息都有一个唯一的偏移量,通过偏移量的顺序递增,来保证消息的顺序排列。
Kafka 的消费者在消费消息时,也是按照偏移量的顺序进行读取的,消费者在处理消息时,会记录自己已经消费的偏移量位置,以便在下次继续从正确的位置读取未消费的消息。
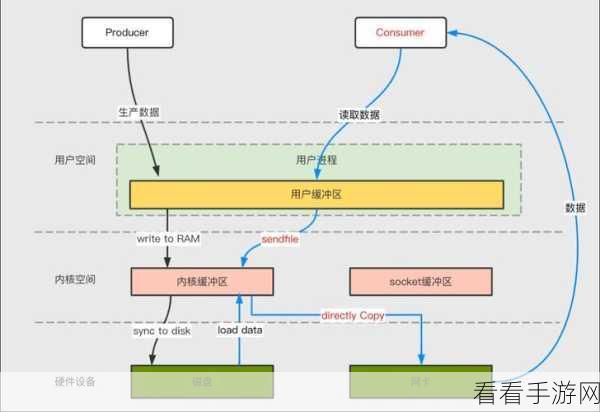
在实际应用中,为了确保消息能够准确无误地发送到指定的分区,需要在发送消息时进行精心的设计,可以根据消息的关键属性来确定分区,从而实现顺序消息的发送。
还需要合理配置 Kafka 的相关参数,以优化顺序消息的处理性能,比如调整消息的批量发送大小、设置合适的副本数量等。
深入掌握 Kafka 顺序消息的实现原理和技巧,对于构建高效可靠的分布式系统具有重要意义。
文章参考来源:相关技术文档及社区讨论。
