深度解析,Flink 与 Kafka 数据同步的精妙之道
在当今的大数据处理领域,Flink 和 Kafka 的结合应用日益广泛,而其中数据同步环节至关重要。
Flink 和 Kafka 作为大数据处理中的关键组件,它们之间的数据同步问题备受关注。
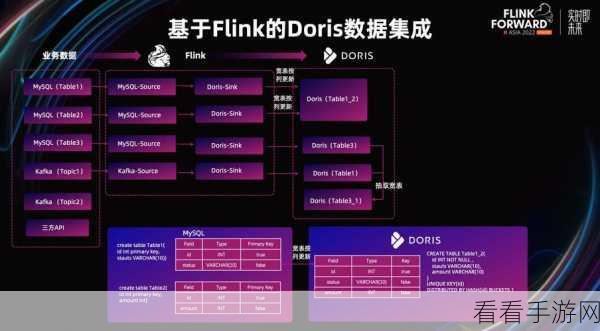
想要实现 Flink 和 Kafka 之间高效的数据同步,我们需要从多个方面入手。
要明确数据同步的目标和需求,不同的业务场景对数据同步的要求可能各不相同,有的需要实时性高,有的则更注重数据的准确性和完整性,在开始同步之前,必须清晰地定义好数据同步的目标,例如是要实现数据的实时流转,还是要进行批量的数据迁移。
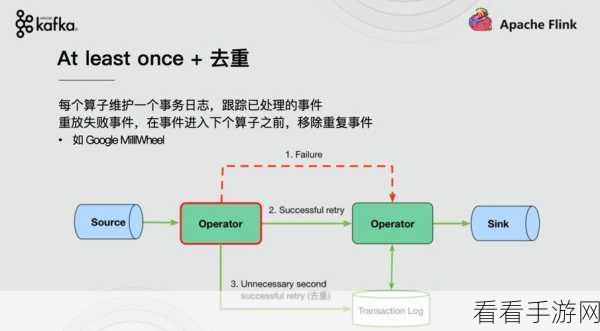
了解 Flink 和 Kafka 的特性是关键,Flink 具有强大的流处理能力,能够实现低延迟的数据处理;而 Kafka 则以其高吞吐量和可靠的消息存储而闻名,只有深入掌握它们的特点,才能更好地利用它们进行数据同步。
合理配置参数也是必不可少的,调整 Flink 的并行度、设置 Kafka 的分区数量和副本因子等,这些参数的设置直接影响到数据同步的性能和效率。
还需要注意数据格式的兼容性,确保 Flink 读取和写入 Kafka 中的数据格式是相互匹配的,避免因为格式不兼容导致的数据丢失或错误。
进行充分的测试和监控,在实际应用中,要对数据同步的效果进行实时监控,及时发现并解决可能出现的问题,确保数据同步的稳定和可靠。
实现 Flink 和 Kafka 之间的数据同步并非易事,需要综合考虑多个因素,从明确目标到合理配置,再到持续监控,每个环节都不容忽视,只有这样,才能在大数据处理中充分发挥它们的优势,实现高效、准确的数据同步。
文章参考来源:大数据处理相关技术文档及实践经验总结。
