Python 分布爬虫安全防护秘籍大揭秘
在当今数字化的时代,Python 分布爬虫技术被广泛应用,但随之而来的安全问题也日益凸显,了解如何进行安全防护至关重要。
Python 分布爬虫在数据采集过程中面临诸多风险,可能会遭遇反爬虫机制的阻拦,导致爬虫无法正常运行;还可能因频繁访问而被目标网站封禁 IP,影响后续的数据获取,若未能妥善处理爬虫获取的数据,还有可能引发法律纠纷。

要保障 Python 分布爬虫的安全,需要从多个方面入手,首先是合理设置爬虫的访问频率,模拟人类正常的访问行为,避免被目标网站识别为恶意爬虫,要使用代理 IP 池,当一个 IP 被封禁时,能够及时切换到其他可用的 IP 继续工作,对于获取到的数据,务必遵循相关法律法规和网站的使用条款,确保数据的使用合法合规。
在技术层面,采用验证码识别技术来应对目标网站的验证要求也是一种有效的手段,不断优化爬虫的算法和代码,提高爬虫的效率和稳定性,减少出错的可能性。
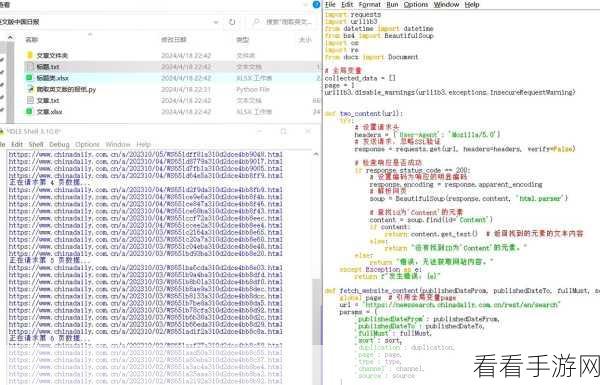
时刻关注目标网站的规则变化,及时调整爬虫的策略也是必不可少的,因为很多网站会不定期更新反爬虫机制,如果不能及时跟进,就可能导致爬虫失效。
只有综合运用多种方法,全面考虑各种可能出现的问题,才能确保 Python 分布爬虫的安全运行,为我们的数据采集工作提供有力的支持。
参考来源:行业相关技术资料及经验总结
