Stream Kafka 吞吐量提升秘籍大揭秘
Stream Kafka 在数据处理和传输中扮演着重要角色,而如何提高其吞吐量一直是开发者们关注的焦点。
想要提升 Stream Kafka 的吞吐量,合理配置资源是关键,要根据实际的业务需求和硬件条件,为 Broker 分配足够的内存和 CPU 资源,内存不足可能导致数据缓冲不畅,而 CPU 性能不够则会影响处理速度。
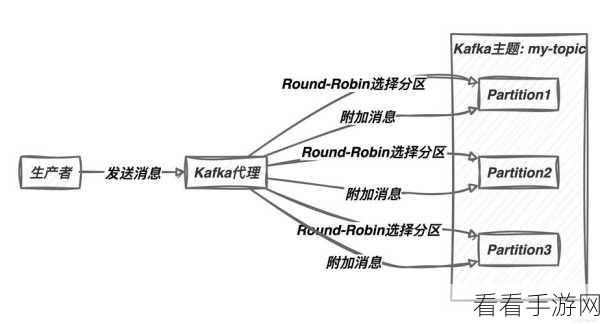
优化生产者和消费者的参数设置同样重要,生产者方面,适当调整批量发送的大小和间隔,可以减少网络开销,提高发送效率,消费者方面,合理设置拉取数据的频率和批量大小,既能保证数据的及时性,又能避免过度消耗资源。
数据分区策略也会对吞吐量产生影响,合理的分区数量和分布能够使数据均匀分布在各个节点上,充分发挥集群的并行处理能力,从而提升整体的吞吐量。
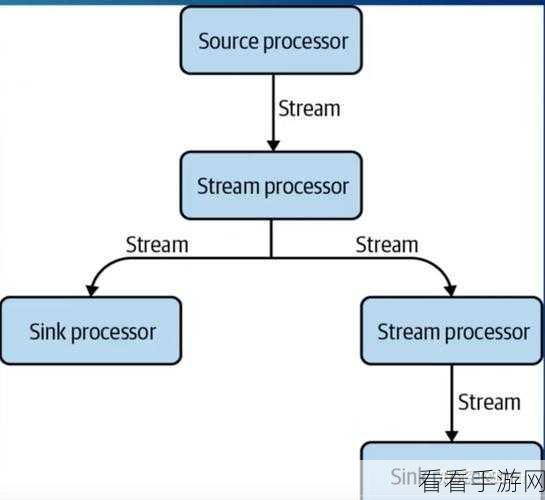
确保网络的稳定性和高效性也不容忽视,低延迟、高带宽的网络环境能够减少数据传输的时间,为提高吞吐量提供有力保障。
在实际应用中,还需要不断地进行测试和优化,通过监控系统指标,如吞吐量、延迟等,及时发现问题并进行针对性的调整。
提高 Stream Kafka 的吞吐量需要综合考虑多个方面,从资源配置到参数优化,再到网络环境和持续的监控改进,每一个环节都至关重要。
参考来源:相关技术论坛及官方文档。
