Stream Kafka 高效实现攻略秘籍
Stream Kafka 作为一种强大的数据处理工具,在现代应用开发中发挥着重要作用,想要实现它,需要掌握一系列关键技巧和方法。
Stream Kafka 的实现并非易事,需要对其原理和相关技术有深入的理解,要明确数据的来源和处理目标,这意味着清楚知道哪些数据需要通过 Kafka 进行流转,以及最终要达到怎样的处理效果。
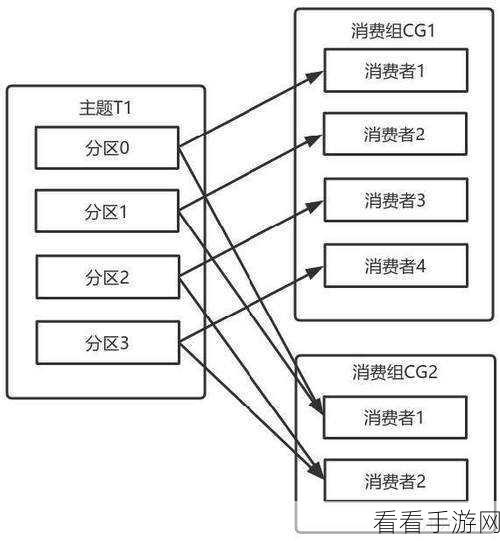
合理配置 Kafka 的参数至关重要,设置合适的分区数量、副本因子以及消息的保留策略等,这些参数的调整直接影响着系统的性能和数据的可靠性。
对于数据的序列化和反序列化要选择合适的方式,高效的序列化和反序列化方法能够提升数据传输和处理的效率,减少不必要的开销。
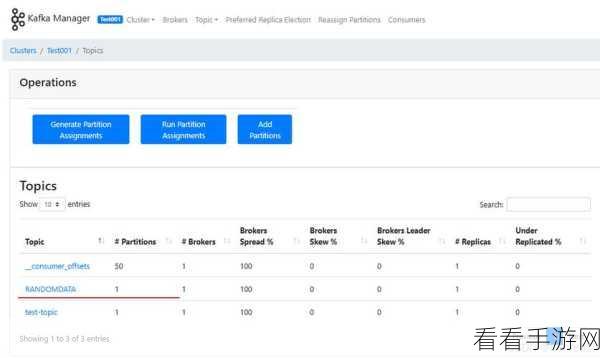
错误处理和监控机制也是不可或缺的部分,及时发现和处理异常情况,通过有效的监控手段了解系统的运行状态,能够保障 Stream Kafka 的稳定运行。
在实际的开发过程中,还需要结合具体的业务需求和系统架构,对 Stream Kafka 进行灵活的运用和优化,只有不断实践和总结经验,才能真正掌握 Stream Kafka 的实现技巧,为应用开发带来强大的支持。
文章参考来源:相关技术文档及个人实践经验总结。
