探索 Flink 与 Kafka 的完美集成之道
在当今的数据处理领域,Flink 和 Kafka 的集成成为了众多开发者关注的焦点,它们的结合能够为数据处理带来高效、可靠的解决方案。
Flink 作为一款强大的流处理框架,具备出色的实时处理能力,而 Kafka 则是分布式的消息队列系统,常用于数据的收集和分发。
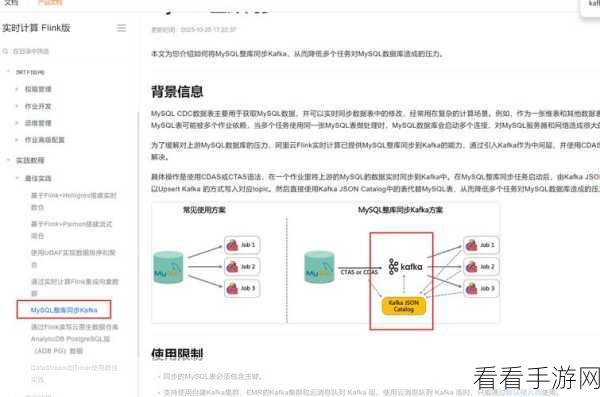
要实现 Flink 和 Kafka 的集成,首先需要了解它们各自的特点和优势,Flink 支持精确的事件时间处理和丰富的窗口操作,能够应对复杂的流处理场景,Kafka 则以其高吞吐量、可扩展性和容错性而闻名。
在实际的集成过程中,配置正确的连接参数至关重要,这包括 Kafka 的主题名称、分区信息,以及 Flink 的数据源和接收器配置等。
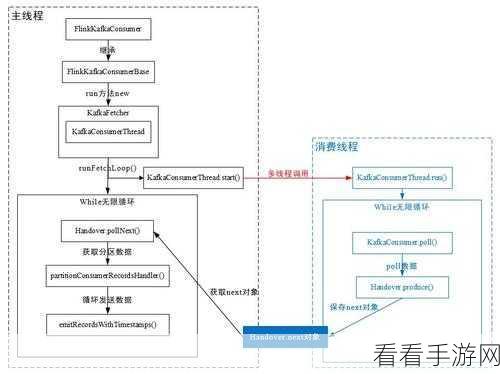
还需要考虑数据的序列化和反序列化方式,以确保数据在 Flink 和 Kafka 之间的传输准确无误。
对于处理过程中的数据一致性和容错性,也需要进行精心的设计和处理,通过合理设置检查点和恢复机制,可以保证在系统故障时能够快速恢复并继续处理数据。
成功地将 Flink 和 Kafka 集成需要对两者的深入理解和精细的配置,只有这样才能充分发挥它们的优势,为数据处理带来更出色的性能和可靠性。
文章参考来源:相关技术文档及开发者社区经验分享。
