Python 和 JS 爬虫数据解析的绝妙技法大揭秘
在当今数字化的时代,数据的获取和分析变得至关重要,而爬虫技术作为获取数据的有效手段,其数据解析方法更是备受关注,特别是 Python 和 JS 这两种广泛应用的编程语言,它们在爬虫数据解析方面有着丰富多样的方法。
Python 语言在爬虫数据解析中具有强大的功能,BeautifulSoup 库是常用的解析工具之一,它能够轻松处理 HTML 和 XML 格式的数据,通过简单的语法,就可以准确地提取出所需的信息,正则表达式也是 Python 中用于数据解析的重要方式,其灵活的模式匹配能力可以应对各种复杂的数据结构。
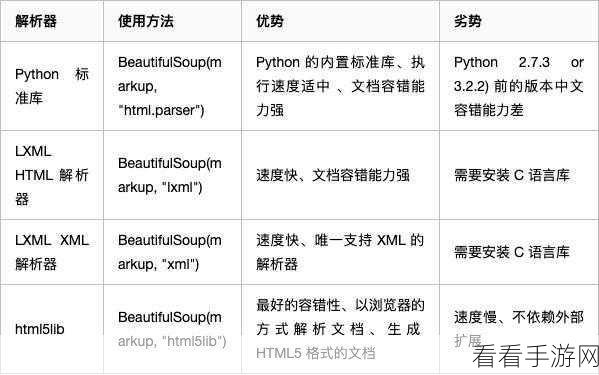
JS 语言同样为爬虫数据解析提供了有力支持。 cheerio 库类似于 Python 中的 BeautifulSoup,能够方便地对网页数据进行操作和提取,而使用原生的 JavaScript 方法,如字符串处理和 DOM 操作,也能实现对爬虫数据的有效解析。
无论是 Python 还是 JS,在进行爬虫数据解析时,都需要注意合法性和道德规范,遵循网站的使用规则,避免对服务器造成过大的负担,是每个开发者应尽的责任。
参考来源:相关技术论坛及专业书籍
仅供参考,希望能对您有所帮助,如果您想深入了解更多关于 Python 和 JS 爬虫数据解析的知识,可以进一步查阅专业资料和实践探索。
