深度解析,Flink 与 Kafka 的优劣大揭秘
Flink 和 Kafka 作为大数据领域的重要技术,各自有着独特的特点和应用场景,了解它们的优缺点对于开发者和数据工程师来说至关重要。
Flink 是一个强大的流处理框架,具有出色的实时处理能力,它能够在毫秒级别内处理数据,确保数据的及时性和准确性,Flink 支持精确一次的语义,这意味着数据处理的结果是可靠的,不会出现重复或丢失的情况,Flink 还提供了丰富的 API 和算子,使得开发者能够灵活地构建复杂的流处理应用。
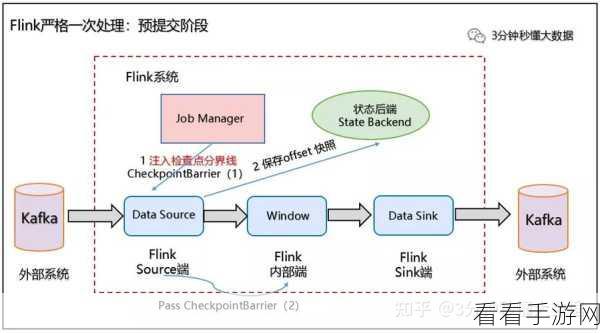
Flink 也并非完美无缺,它的学习曲线相对较陡峭,对于初学者来说可能需要花费一定的时间和精力去掌握,在资源管理方面,Flink 有时可能会出现资源分配不合理的情况,导致系统性能下降。
Kafka 则是一款高吞吐量的分布式消息队列系统,它能够快速地处理大量的消息,并且具有良好的扩展性,可以轻松应对不断增长的数据量,Kafka 的分区机制使得数据的分布和存储更加灵活,提高了系统的容错性和可用性。
不过,Kafka 在数据处理的实时性方面相对较弱,对于一些对实时性要求极高的场景可能不太适用,Kafka 的消息存储机制也存在一定的局限性,可能会导致数据的延迟和丢失。
Flink 和 Kafka 都有各自的优势和不足,在实际应用中,应根据具体的业务需求和场景来选择合适的技术,如果需要强大的实时处理能力和精确的结果,Flink 可能是更好的选择;而如果注重高吞吐量和扩展性,Kafka 则更具优势。
参考来源:大数据技术相关研究资料及行业实践经验。
希望以上内容能满足您的需求,如有其他要求,您可以继续提出。
