Flink 与 Kafka 选型秘籍大揭秘
在当今的大数据处理领域,Flink 和 Kafka 都是备受瞩目的技术,对于许多开发者和企业来说,如何在它们之间做出正确的选型,是一个关键且具有挑战性的问题。
Flink 作为一款优秀的流处理框架,具有出色的实时处理能力和强大的状态管理机制,其能够快速准确地处理源源不断的数据流,为实时分析和决策提供有力支持。
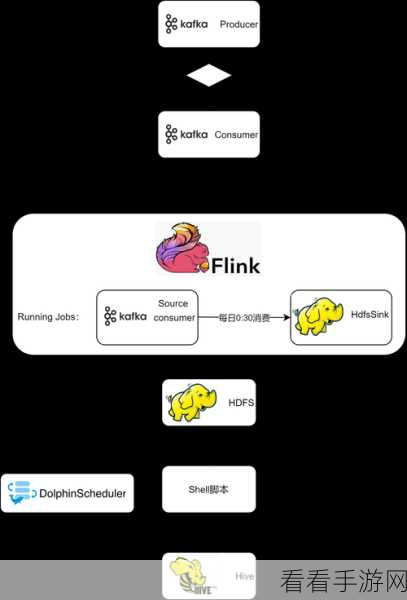
Kafka 则是分布式消息队列的翘楚,以高吞吐量、低延迟和良好的扩展性著称,它能够有效地存储和传递大量的消息数据,为系统的解耦和异步处理提供了可靠的基础。
在进行 Flink 和 Kafka 选型时,需要考虑哪些因素呢?
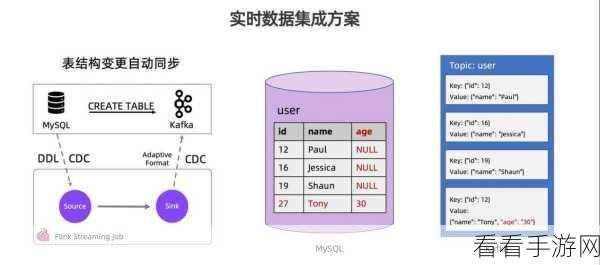
业务需求,如果您的业务对实时性要求极高,需要快速处理和分析数据流,Flink 可能是更合适的选择,但如果您更关注消息的存储和传递,以及系统的解耦,Kafka 则可能更能满足您的需求。
数据规模和处理量,如果您需要处理大规模的数据,并且处理量较大,Flink 的分布式架构和强大的处理能力能够更好地应对挑战,而对于数据量相对较小,且对消息传递的稳定性和可靠性要求较高的情况,Kafka 则表现更为出色。
技术团队的熟悉程度也是一个重要因素,如果团队对某一项技术有更深入的了解和丰富的实践经验,那么在选型时可以优先考虑,这样能够降低开发和维护的成本,提高项目的推进效率。
Flink 和 Kafka 的选型并非一蹴而就,需要综合考虑业务需求、数据规模、处理量以及技术团队等多方面的因素,只有在充分了解自身需求和技术特点的基础上,才能做出最适合的选择,为业务的发展提供有力的技术支撑。
文章参考来源:大数据技术相关书籍及技术论坛。
