掌握多线程 Python 爬虫的监控调试秘籍
多线程 Python 爬虫在数据采集领域扮演着重要角色,但监控与调试是确保其高效稳定运行的关键。
要实现有效的监控与调试,首先得明晰其运行原理,多线程爬虫通过同时启动多个线程来加速数据抓取,但也正因如此,可能会出现线程竞争、资源冲突等问题。
监控方面,重点关注爬虫的请求频率、响应时间以及错误率,通过设置合理的监控指标,可以及时发现爬虫运行中的异常,若请求频率过高,可能会被目标网站识别为恶意爬虫而封禁;响应时间过长则可能意味着网络问题或目标网站的反爬虫机制生效。
调试时,要善于利用 Python 的调试工具,使用 print 语句输出关键变量的值,以便查看爬虫在运行过程中的数据处理是否符合预期,还可以借助 Python 的调试器,如 pdb,逐行调试代码,深入分析爬虫的执行逻辑。
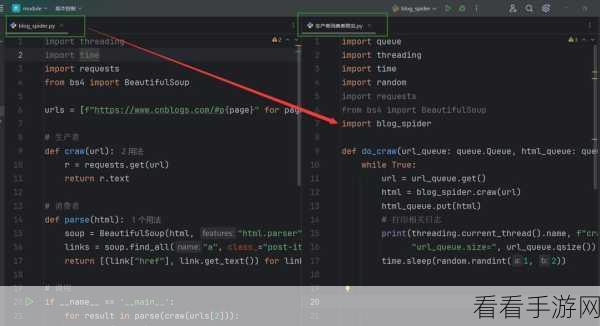
日志记录也是必不可少的,详细的日志能够帮助我们回溯爬虫的运行过程,快速定位问题所在,在记录日志时,应包含爬虫的启动时间、执行步骤、遇到的错误等关键信息。
只有深入理解多线程 Python 爬虫的工作机制,并熟练运用监控与调试的方法,才能让爬虫更加高效、稳定地为我们服务。
文章参考来源:相关 Python 爬虫技术书籍及网络技术论坛。
