深度解析,Kafka 消息幂等对性能的冲击
Kafka 消息幂等性,这个在大数据处理和分布式系统中备受关注的概念,对性能究竟有着怎样的影响?这是众多技术开发者和运维人员都十分关心的问题。
Kafka 作为一种高性能的分布式消息队列,在处理海量数据时展现出了强大的能力,而消息幂等性的引入,虽然在一定程度上保证了数据的准确性和一致性,但不可避免地会对系统性能产生影响。
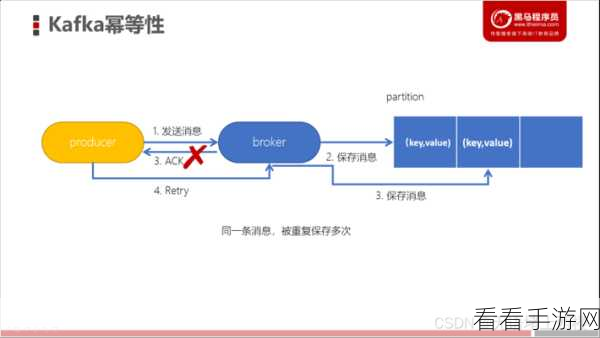
要深入理解这种影响,我们首先需要明确什么是 Kafka 消息幂等性,幂等性就是指对同一操作进行多次执行所产生的结果与执行一次的结果相同,在 Kafka 中,通过一些机制实现了消息的幂等发送和处理,确保消息不会被重复处理。
实现消息幂等性并非毫无代价,在消息发送端,为了保证幂等性,需要额外的标识和处理逻辑,这会增加发送消息的开销,在消息接收端,对幂等消息的识别和过滤也需要消耗一定的计算资源。
幂等性机制还可能导致消息的延迟增加,因为在处理幂等消息时,系统需要进行额外的校验和判断,这会延长消息处理的时间,从而影响整体的处理效率。
为了减轻 Kafka 消息幂等性对性能的影响,可以采取一些优化措施,合理设计幂等标识,减少不必要的开销;优化消息处理流程,提高校验和过滤的效率;根据实际业务需求,灵活调整幂等性的级别等。
Kafka 消息幂等性在保障数据准确性的同时,确实会对性能产生一定的影响,但通过合理的设计和优化,我们可以在准确性和性能之间找到一个较好的平衡,从而充分发挥 Kafka 在分布式系统中的优势。
文章参考来源:相关技术文档及行业研究报告。
