Python Spider 爬虫并发处理秘籍大公开
Python Spider 爬虫在数据采集领域发挥着重要作用,而实现并发处理则能大大提升其效率,让我们一同深入探究 Python Spider 爬虫并发处理的实现方法。
要理解 Python Spider 爬虫的并发处理,首先得清楚什么是并发,并发意味着在同一时间段内,多个任务能够同时进行,而非严格意义上的同时执行,在爬虫中,通过并发处理,可以同时发送多个请求,获取数据,从而节省时间,提高效率。
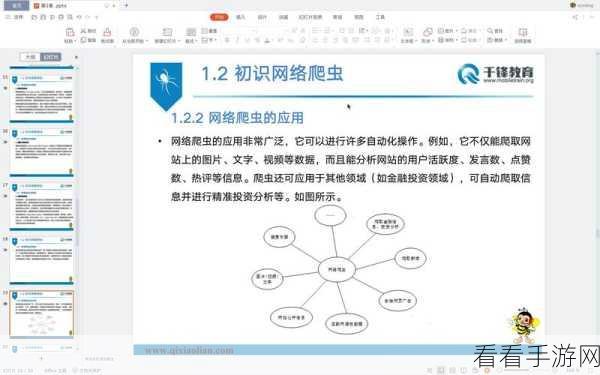
实现 Python Spider 爬虫的并发处理,有多种方式可供选择,多线程和多进程是常见的方法,多线程能够在一个进程内创建多个线程,每个线程可以独立执行任务,而多进程则是创建多个独立的进程来执行任务。
在使用多线程时,需要注意线程安全问题,由于多个线程共享资源,可能会出现数据竞争等问题,为了避免这些问题,可以使用线程锁等机制来保证数据的一致性。
多进程方式相对来说资源隔离性更好,但也需要注意进程间通信的效率和成本。
还可以借助一些第三方库来实现爬虫的并发处理,使用 asyncio 库,通过异步编程的方式,能够更加高效地处理并发任务。
实现 Python Spider 爬虫的并发处理需要综合考虑多种因素,根据具体的需求和场景选择合适的方法,在实际应用中,不断测试和优化,以达到最佳的效果。
文章参考来源:相关技术文档及专业论坛讨论。
仅供参考,您可以根据实际需求进行调整和修改。
