Python 可视化爬虫突破复杂网页结构的秘诀
在当今数字化时代,网页信息的获取变得愈发重要,而 Python 可视化爬虫作为一种强大的工具,在应对复杂网页结构时面临着诸多挑战。
想要成功运用 Python 可视化爬虫处理复杂网页,我们需要深入了解网页结构的特点,复杂网页通常包含多层嵌套、动态加载内容以及各种反爬虫机制,这使得数据的抓取变得困难重重。
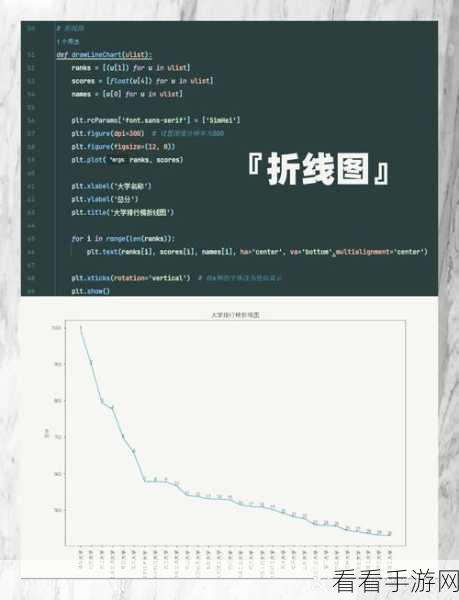
如何让 Python 可视化爬虫在复杂网页中“游刃有余”呢?关键在于选择合适的爬虫框架和工具,Scrapy 框架具有强大的功能和灵活的配置选项,能够帮助我们应对各种复杂情况,还需要熟练掌握网页解析技术,如 BeautifulSoup 和 XPath 等,以便准确提取所需的数据。
设置合理的请求头和模拟用户行为也是必不可少的,通过模拟正常用户的访问频率、浏览器标识等信息,可以有效降低被网站识别为爬虫的风险,对于动态加载的内容,要善于利用浏览器开发者工具分析网络请求,找到数据的接口,从而实现精准抓取。
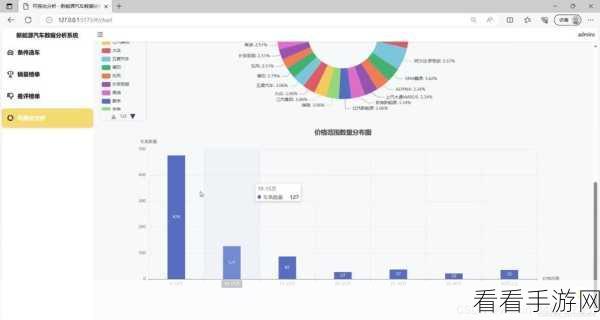
在处理复杂网页结构时,还需注意数据的清洗和整理,抓取到的数据可能存在格式不一致、重复或错误等问题,需要进行有效的清洗和整理,以确保数据的质量和可用性。
要让 Python 可视化爬虫在复杂网页结构中发挥出色,需要综合运用多种技术和策略,不断实践和优化,只有这样,才能在海量的网页数据中获取到有价值的信息。
文章参考来源:相关技术论坛及专业书籍。
