深度解析,Hive MapJoin 应对复杂查询的秘籍
Hive MapJoin 作为大数据处理中的重要技术,在处理复杂查询时有着独特的优势和挑战。
Hive MapJoin 之所以能够在复杂查询中发挥关键作用,是因为它采用了特定的算法和优化策略,其通过将小表加载到内存中,与大表进行连接操作,大大提高了查询的效率。
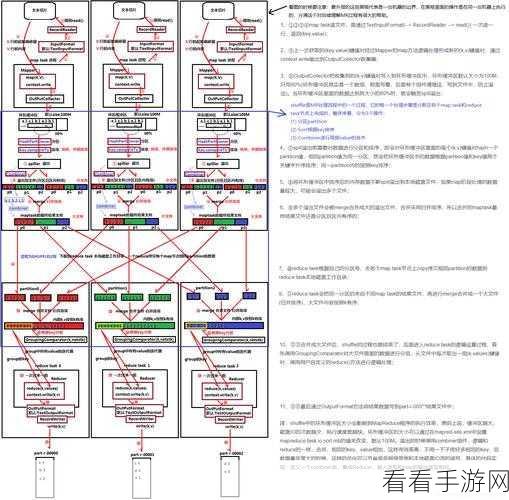
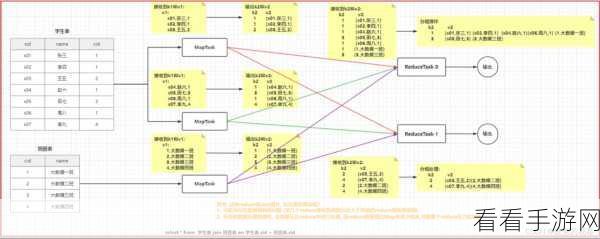
要理解 Hive MapJoin 处理复杂查询的机制,需要先明确其工作原理,它会在 Map 阶段将小表的数据分发到各个 Map 任务中,然后在 Map 任务中与大表的数据进行连接,这样的分布式处理方式,使得大规模数据的复杂查询能够快速完成。
在实际应用中,为了更好地利用 Hive MapJoin 处理复杂查询,还需要注意一些关键因素,合理选择小表和大表,确保小表能够被有效地加载到内存中,对于数据的分布和倾斜情况也要有清晰的认识,以便进行针对性的优化。
参数的设置对于 Hive MapJoin 的性能也有着重要影响,通过调整相关参数,如 mapjoin.smalltable.filesize 等,可以进一步提升处理复杂查询的效果。
掌握 Hive MapJoin 处理复杂查询的技巧,需要深入理解其工作原理,结合实际应用场景进行优化,并合理设置相关参数,只有这样,才能充分发挥其优势,高效地完成复杂的大数据查询任务。
参考来源:相关技术文档及实践经验总结
