揭秘 Spark 算法,破解高并发难题的关键策略
在当今数字化时代,高并发场景已成为众多应用面临的严峻挑战,而 Spark 算法作为一种强大的处理工具,其应对高并发的能力备受关注。
Spark 算法在处理高并发时,有着独特的优势和策略,要理解 Spark 算法如何应对高并发,首先需要了解其核心原理,Spark 算法基于分布式计算框架,能够将大规模数据处理任务分解为多个小任务,并在集群中的多个节点上并行执行,这种分布式的处理方式,为应对高并发提供了坚实的基础。
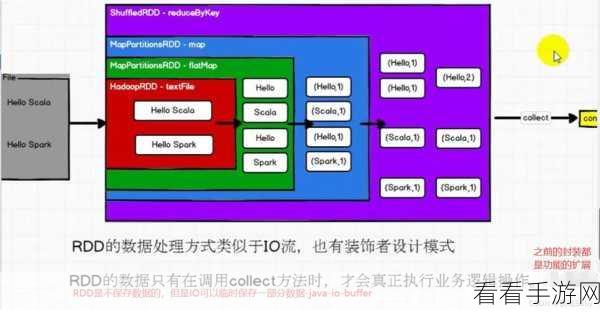
Spark 算法还采用了高效的内存管理机制,在处理高并发数据时,能够有效地利用内存资源,减少数据的读写开销,从而提高处理效率,其还具备优化的任务调度策略,能够根据节点的负载情况,合理分配任务,确保整个集群的资源得到充分利用。
为了进一步提升应对高并发的能力,Spark 算法还支持数据分区和缓存技术,通过合理的数据分区,可以将数据均匀分布到不同的节点上,避免某些节点负载过高,而缓存技术则可以将经常使用的数据存储在内存中,减少重复计算,加快处理速度。
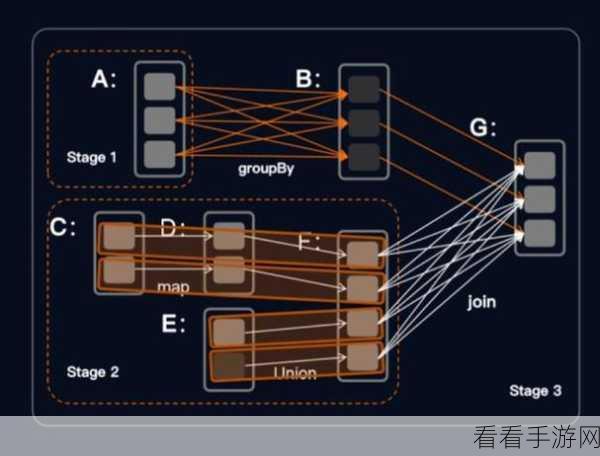
在实际应用中,要充分发挥 Spark 算法应对高并发的优势,还需要结合具体的业务场景进行优化和调整,根据数据特点选择合适的分区方式,调整缓存策略以适应不同的访问模式等。
深入理解和掌握 Spark 算法应对高并发的方法和策略,对于提升大数据处理能力和应用性能具有重要意义。
文章参考来源:相关技术文档及行业研究报告。
