深入探究,Spark 函数内存管理的奥秘
Spark 函数的内存管理是一个至关重要的技术问题,在大数据处理和分析的领域中,高效的内存管理能够显著提升 Spark 应用的性能和效率。
内存管理对于 Spark 函数的运行效果有着直接的影响,如果内存分配不合理,可能会导致数据溢出、任务失败或者性能下降等问题,深入理解 Spark 函数的内存管理机制对于开发者和运维人员来说是必不可少的。
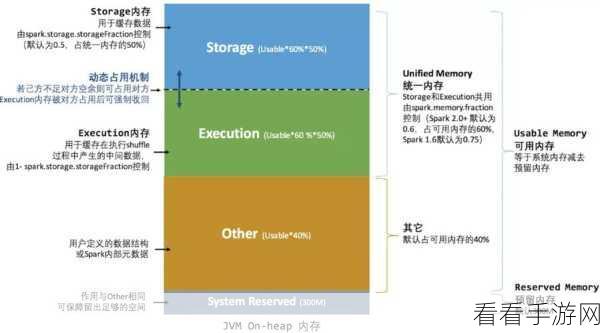
要想有效地管理 Spark 函数的内存,需要了解一些关键的概念和技术,内存的分区和存储方式,不同的数据结构在内存中的存储特点,以及如何根据数据量和计算需求合理地调整内存配置参数等。
在 Spark 中,内存的分配和回收是由其内部的机制自动完成的,但这并不意味着开发者可以完全依赖自动管理而不进行任何干预,通过设置合适的参数,如 executor-memory、spark.memory.fraction 等,可以对内存的使用进行更精细的控制。
还需要关注数据的缓存策略,合理地缓存经常使用的数据可以减少重复计算,提高性能,但过度的缓存又可能导致内存不足,所以需要在缓存和内存使用之间找到一个平衡。
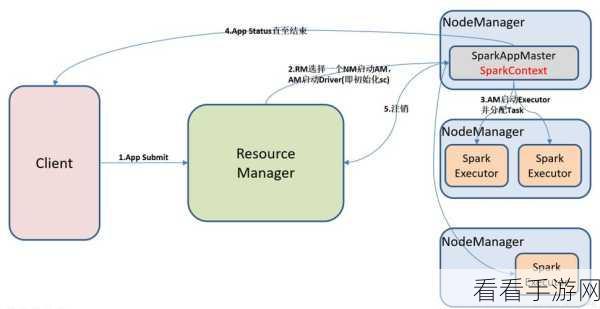
对于大型的 Spark 应用,还需要考虑到集群环境中各个节点的内存资源分布情况,通过合理地分配任务到不同的节点,充分利用各个节点的内存资源,来实现整个应用的高效运行。
深入研究和掌握 Spark 函数的内存管理,能够让我们在使用 Spark 进行数据处理和分析时更加得心应手,充分发挥其强大的功能,提高工作效率和质量。
参考来源:相关技术文档及权威专家的经验分享。
仅供参考,您可以根据实际需求进行调整和修改。
