深度解析,Spark 处理数据倾斜的精妙策略
数据处理是当今数字化时代的关键环节,而 Spark 在其中扮演着重要角色,数据倾斜问题常常成为 Spark 应用中的棘手挑战。
Spark 处理数据倾斜的方法多种多样,使用随机前缀和二次聚合是一种有效的策略,通过给可能导致倾斜的键添加随机前缀,将数据分散到不同的分区,然后进行二次聚合,可以显著减少倾斜的影响。
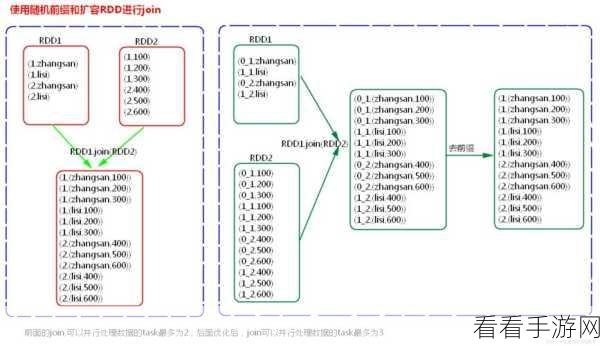
调整并行度也是解决数据倾斜的重要手段,合理增加任务的并行度,能够使数据更均匀地分布在各个节点上,从而避免部分节点承担过重的任务。
过滤掉可能导致倾斜的异常数据也是一个可行的思路,在数据预处理阶段,识别并剔除那些数量巨大但价值相对较低的数据,能够减轻后续处理中的倾斜压力。
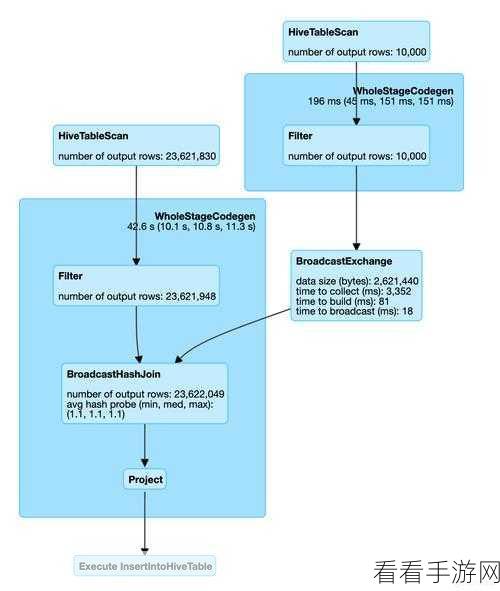
还有一种方法是使用加盐操作,将数据与随机值结合,改变数据的分布,使得原本集中的热点数据分散开来,从而解决数据倾斜问题。
解决 Spark 数据倾斜需要综合运用多种策略,并根据具体的数据特点和应用场景进行选择和优化,只有这样,才能充分发挥 Spark 的性能优势,实现高效的数据处理。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整。
