探索 Hadoop 与 Spark 的完美搭配秘籍
在当今大数据时代,Hadoop 和 Spark 成为了处理海量数据的重要工具,如何实现它们的有效搭配,却是众多开发者面临的难题。
Hadoop 拥有强大的分布式存储能力,而 Spark 则以其高效的计算性能著称,要想让二者协同工作,发挥出最大的优势,需要深入了解它们的特点和适用场景。

了解数据的特点至关重要,不同类型和规模的数据,适合不同的处理方式,对于大规模的静态数据,Hadoop 的分布式存储能够提供稳定可靠的支持;而对于需要快速处理和实时分析的数据,Spark 的内存计算则能大幅提高效率。
在架构设计上要合理规划,考虑到数据的流入、处理和流出,设计一个高效的流程,将原始数据先存储在 Hadoop 的 HDFS 中,然后通过 Spark 进行计算和分析,最后将结果输出到合适的存储介质中。
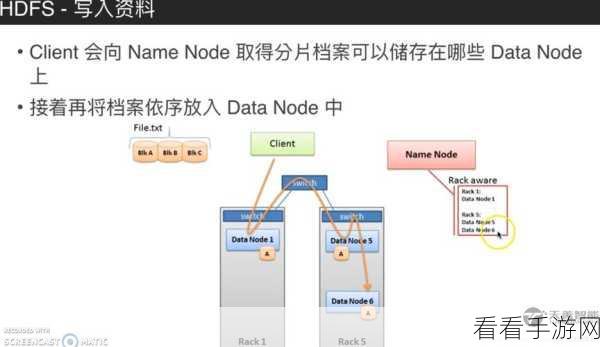
资源分配也是关键,要根据实际的业务需求和硬件资源,合理分配 Hadoop 和 Spark 的计算资源和存储资源,避免出现资源竞争和浪费的情况。
不断的测试和优化是必不可少的,通过实际的业务场景进行测试,发现潜在的问题,并针对性地进行优化,以达到最佳的性能表现。
实现 Hadoop 与 Spark 的完美搭配并非一蹴而就,需要综合考虑多方面的因素,不断探索和实践,才能在大数据处理中取得优异的成果。
文章参考来源:大数据处理相关技术文档及行业经验分享。
仅供参考,您可以根据实际需求进行调整和修改。
