掌握关键技巧,攻克 Hive Shuffle 数据倾斜难题
Hive Shuffle 数据倾斜是在大数据处理中经常遭遇的棘手问题,要有效地避免这一状况,需要我们深入理解其原理,并运用合适的策略。
数据倾斜产生的原因多种多样,数据分布不均匀是主要因素之一,当某些键值的数据量远远超过其他键值时,就容易导致任务在处理这些数据时耗费大量时间,从而影响整体性能。

为了避免 Hive Shuffle 数据倾斜,我们可以从多个方面入手,在进行数据预处理时,尽量确保数据的分布相对均衡,通过对数据进行采样分析,提前了解数据的分布情况,然后采取相应的处理措施,如对数据进行重新分区或者过滤掉一些异常值。
优化 SQL 语句也是至关重要的,合理地调整连接条件、使用合适的聚合函数以及避免不必要的操作,都能够有效地减少数据倾斜的发生概率。
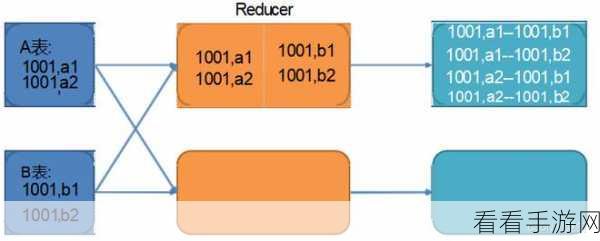
还可以考虑调整 Hive 的配置参数,增加并行度、调整内存分配等,以适应不同的数据处理场景。
避免 Hive Shuffle 数据倾斜需要综合运用多种方法,不断地进行实践和优化,才能达到理想的效果。
参考来源:相关技术文档及个人实践经验总结
