深度解析,Hive Analyze 与分区裁剪的精妙之处
Hive Analyze 与分区裁剪是在大数据处理中非常重要的技术手段,它们能够有效地提升数据处理的效率和准确性,为数据分析和业务决策提供有力支持。
Hive Analyze 主要用于收集和分析表或分区的统计信息,通过对数据分布、行数、列值等方面的统计,可以让查询优化器更好地制定执行计划,从而提高查询性能,比如说,当我们对一个拥有大量数据的表进行查询时,如果事先进行了 Hive Analyze 操作,优化器就能更准确地评估不同执行路径的成本,选择最优的执行方式,减少不必要的计算和数据读取。
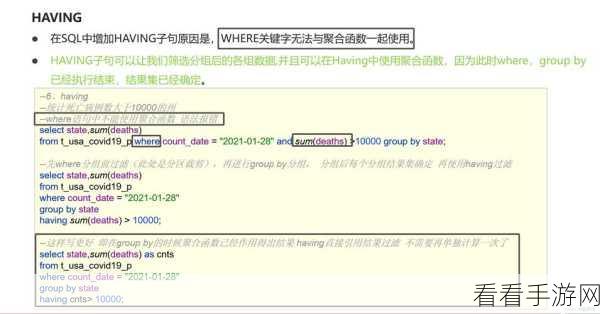
分区裁剪则是根据查询条件,只读取相关分区的数据,避免对整个表进行扫描,这在处理大规模数据时能节省大量的时间和资源,在一个按日期分区的表中,如果查询只针对特定日期范围的数据,分区裁剪就会发挥作用,只读取对应日期分区的数据,而不会去读取其他无关分区。
要有效地应用 Hive Analyze 和分区裁剪,需要注意一些关键要点,要合理规划表的分区策略,确保分区能够与业务查询需求紧密结合,定期执行 Hive Analyze 操作,以保证统计信息的准确性和及时性,还需要对查询语句进行优化,充分利用分区裁剪的特性。
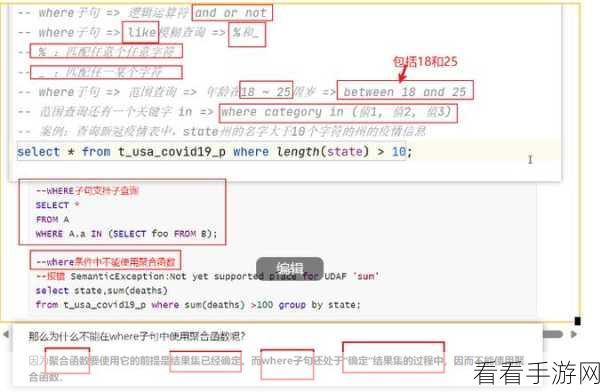
Hive Analyze 和分区裁剪是提升大数据处理效率的重要法宝,只有深入理解和熟练运用这两项技术,才能在大数据处理的海洋中畅游无阻,为业务发展提供强大的数据支持。
参考来源:相关技术文档及实践经验总结。
