深度解析,Spark 函数在批处理与流处理中的表现
在当今的数据处理领域,Spark 函数的应用备受关注,Spark 函数是否支持批处理和流处理成为了众多开发者和数据分析师关心的重要问题。
Spark 函数具备强大的功能,为数据处理提供了高效且灵活的解决方案,它在处理大规模数据时展现出了卓越的性能。
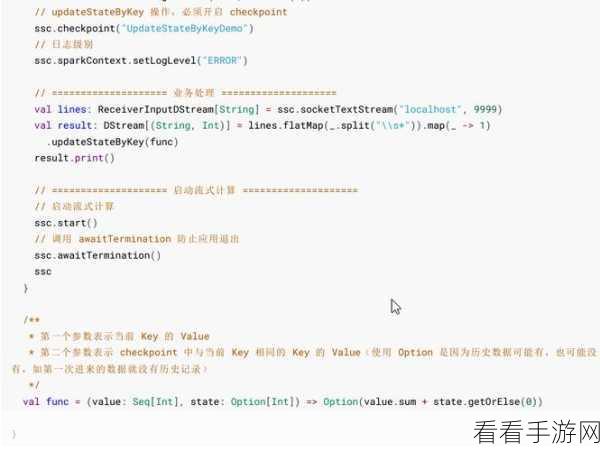
要深入理解 Spark 函数对批处理和流处理的支持,我们需要先了解批处理和流处理的特点,批处理是对大量数据进行一次性处理,适用于对数据时效性要求不高,但需要全面、深入分析的场景,流处理则是实时处理源源不断产生的数据,强调数据的实时性和快速响应。
Spark 函数在批处理方面表现出色,它能够有效地处理大规模的静态数据,通过优化的算法和分布式计算框架,快速完成复杂的计算任务,在进行数据分析和挖掘时,Spark 函数可以对海量的历史数据进行聚合、关联等操作,为决策提供有力支持。

而在流处理方面,Spark 也提供了相应的支持和组件,它能够实时接收和处理数据流,确保数据的及时性和准确性,通过与其他技术的结合,如 Kafka 等消息队列,Spark 函数可以构建强大的实时数据处理系统。
在实际应用中,选择使用 Spark 函数进行批处理还是流处理,需要根据具体的业务需求和数据特点来决定,如果数据量较大、处理逻辑复杂,且对实时性要求不高,批处理可能是更好的选择,反之,如果需要实时响应和处理不断产生的数据,流处理则更为合适。
Spark 函数在批处理和流处理中都具有重要的作用和价值,深入掌握其特性和应用场景,能够帮助我们更好地应对各种数据处理任务,提升数据处理的效率和质量。
参考来源:相关技术文档及行业研究报告。
仅供参考,您可以根据实际需求进行调整和修改。
