Hive 中自定义 RowNumber 起始值的秘籍大揭秘
在当今的大数据处理领域,Hive 作为一款强大的数据仓库工具,被广泛应用于各种数据分析场景,RowNumber 函数在数据排序和分组处理中发挥着重要作用,如何自定义 RowNumber 的起始值却成为许多开发者面临的难题,让我们一同深入探索这个问题的解决之道。
中心句:Hive 在大数据处理领域应用广泛,RowNumber 函数重要,但自定义起始值是难题。
要实现自定义起始值,我们首先需要了解 Hive 中 RowNumber 函数的基本原理,RowNumber 函数会为结果集中的每一行分配一个唯一的连续整数编号,从 1 开始递增,但在某些特定的业务场景中,我们可能希望从指定的数值开始编号,这就需要对其进行自定义设置。
中心句:了解 RowNumber 函数基本原理,明确自定义起始值需求。
具体应该如何操作呢?我们可以通过在查询语句中添加一些特定的参数和逻辑来实现自定义起始值,使用窗口函数的 OVER 子句,并结合一些条件判断和计算表达式,就能够灵活地控制起始值的设定。
中心句:通过查询语句中特定参数和逻辑可实现自定义起始值。
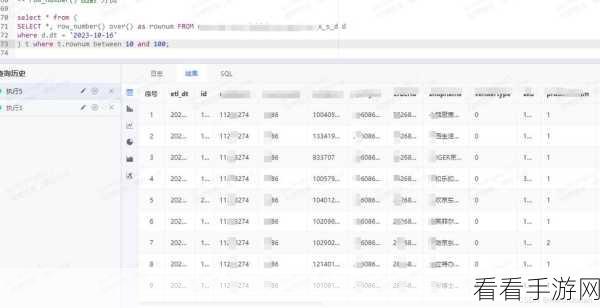
为了更清晰地说明这个过程,我们来看一个具体的示例,假设我们有一张名为“sales_data”的表,包含“sales_id”、“sales_amount”和“sales_date”等列,现在我们想要按照“sales_amount”降序排列,并从 5 开始为每行分配 RowNumber,查询语句可以这样写:
SELECT
*,
ROW_NUMBER() OVER (ORDER BY sales_amount DESC) + 4 AS custom_row_number
FROM
sales_data;中心句:通过具体示例清晰展示自定义起始值的操作过程。
通过这个示例,相信您对如何在 Hive 中自定义 RowNumber 的起始值有了更直观的认识和理解,但需要注意的是,实际应用中可能会遇到各种复杂的情况,需要根据具体的业务需求和数据特点进行灵活调整和优化。
中心句:示例助理解,实际应用需灵活调整优化。
掌握 Hive 中自定义 RowNumber 起始值的方法,将为您在数据处理和分析工作中带来更多的便利和效率提升,希望本文的介绍能够对您有所帮助。
文章参考来源:Hive 官方文档及相关技术论坛。
