深度剖析,Flink 与 Spark 性能激战谁更强
在当今大数据处理领域,Flink 和 Spark 无疑是两颗耀眼的明星,它们都具备强大的功能,但在性能方面却各有千秋。
Flink 和 Spark 在数据处理方式上存在显著差异,Flink 采用了基于流的处理模型,能够实时处理源源不断的数据,具有出色的低延迟特性,而 Spark 则更擅长批处理,对于大规模数据的批量处理效率颇高。
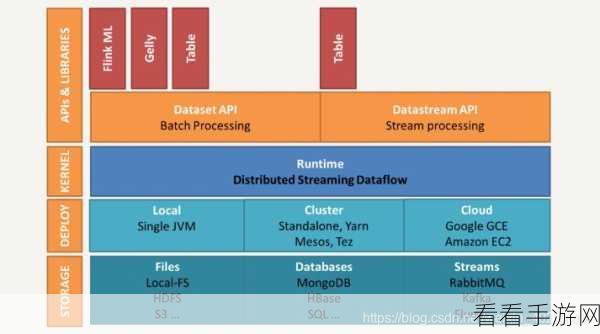
数据吞吐量方面,Spark 在处理大规模数据时表现出色,能够高效地完成复杂的计算任务,但 Flink 在处理小批量、高频次的数据时,能够更快地给出结果,响应更加迅速。
资源利用效率也是两者性能对比的重要方面,Flink 对内存的管理更加精细,能够有效地避免内存溢出等问题,Spark 则在资源分配和调度上有其独特的策略,能够充分利用集群资源。
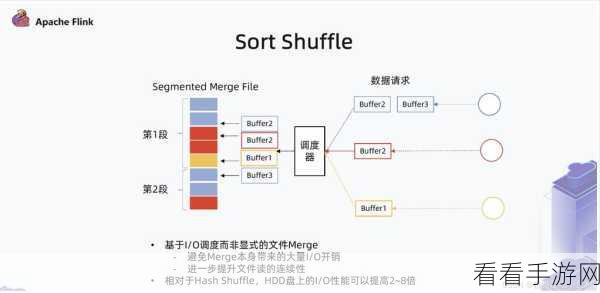
在容错机制上,Flink 提供了精确一次的语义保证,确保数据处理的准确性和完整性,Spark 也具备良好的容错能力,但在某些复杂场景下,可能不如 Flink 表现稳定。
Flink 和 Spark 的性能对比并非简单的谁优谁劣,而是要根据具体的应用场景和需求来选择,如果您的业务对实时性要求极高,Flink 可能是更好的选择;若您需要处理大规模的批处理任务,Spark 或许能发挥更大的优势。
参考来源:相关技术文档及行业研究报告。
