探究 Python BeautifulSoup 爬虫的高效性之谜
Python BeautifulSoup 爬虫在数据获取领域备受关注,但其效率问题一直是开发者们探讨的焦点。
Python BeautifulSoup 爬虫的应用场景广泛,从网页数据采集到信息分析,都能发挥重要作用,关于它的效率,众说纷纭。
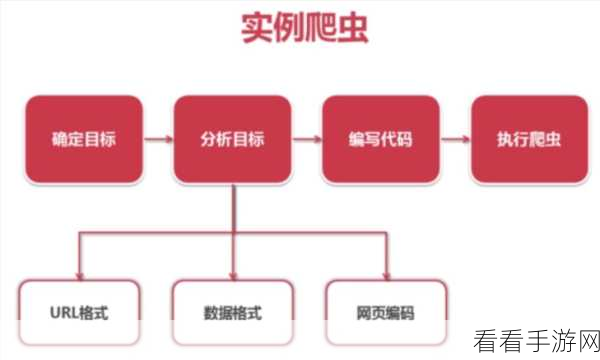
要深入了解 Python BeautifulSoup 爬虫的效率,我们需要从多个方面进行分析,其运行速度受到目标网页结构和数据量的影响,如果网页结构复杂,数据量巨大,那么爬虫的处理时间可能会相应增加,代码的优化程度也是关键因素,合理的代码编写和算法选择能够显著提升爬虫的效率,网络环境的稳定性也会对爬虫的性能产生影响。
在实际应用中,为了提高 Python BeautifulSoup 爬虫的效率,开发者可以采取一些有效的策略,对网页数据进行预处理,去除不必要的信息,减少爬虫的处理负担,利用多线程或多进程技术,并行处理数据,能够加快爬虫的运行速度。
选择合适的解析器也是提升效率的重要一环,不同的解析器在处理不同类型的网页时,性能表现可能有所差异,开发者需要根据实际情况进行选择和测试。
Python BeautifulSoup 爬虫的高效性并非绝对,而是受到多种因素的综合影响,只有在充分了解这些因素,并采取相应的优化措施,才能让爬虫在数据获取中发挥出最佳性能。
文章参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整和修改。
