Python 可视化爬虫,数据库存储优化秘籍大揭秘
Python 可视化爬虫在数据采集和处理中发挥着重要作用,而优化其数据库存储更是提升效率和性能的关键。
要理解 Python 可视化爬虫的数据库存储优化,得先明确其面临的挑战,常见的问题包括数据量庞大、存储结构不合理以及访问速度慢等,这些挑战不仅影响爬虫的工作效率,还可能导致数据丢失或不准确。
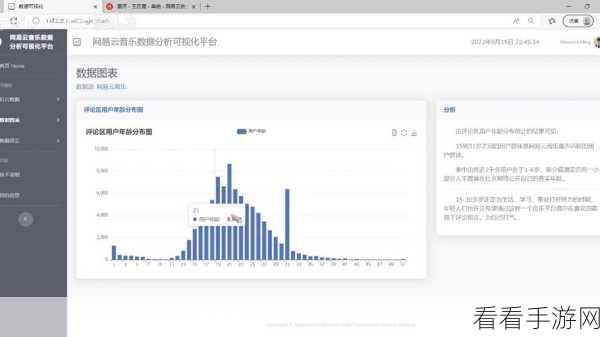
解决这些问题的方法众多,合理选择数据库类型至关重要,对于大规模数据,关系型数据库可能不再适用,NoSQL 数据库如 MongoDB 或 Redis 则更具优势,它们能更好地处理非结构化数据,提供更高的写入和读取速度。
数据存储结构的设计也不能忽视,根据数据的特点和访问模式,建立合适的索引、分区表等,可以大大提高查询效率,要注意数据的压缩和清理,避免无用数据占用过多存储空间。
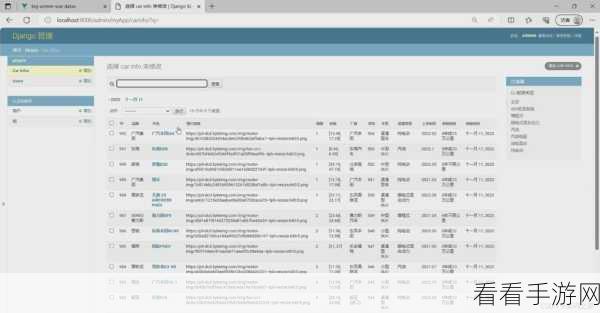
优化数据库连接和事务处理也是关键环节,减少不必要的连接开销,确保事务的正确使用和及时提交,能有效提升数据库操作的性能。
在实际应用中,还需要不断测试和监控,通过性能测试工具,如 MySQL 的 Profiler 或 MongoDB 的 Monitoring 工具,实时了解数据库的运行状态,发现潜在问题并及时调整优化策略。
Python 可视化爬虫的数据库存储优化是一个综合性的工作,需要综合考虑多个因素,并不断实践和改进,才能实现高效、稳定的数据存储和处理。
参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整和修改。
