探究 Kafka 幂等性在跨分区场景下的支持情况
Kafka 幂等性作为一个重要的特性,其在数据处理和消息传递中发挥着关键作用,对于它是否支持跨分区这一问题,引发了众多开发者和技术人员的深入探讨。
Kafka 幂等性旨在确保消息的精确一次处理,避免重复数据的出现,在实际应用中,分区是 Kafka 实现数据分布和负载均衡的重要手段,但当涉及到跨分区操作时,情况变得复杂起来。
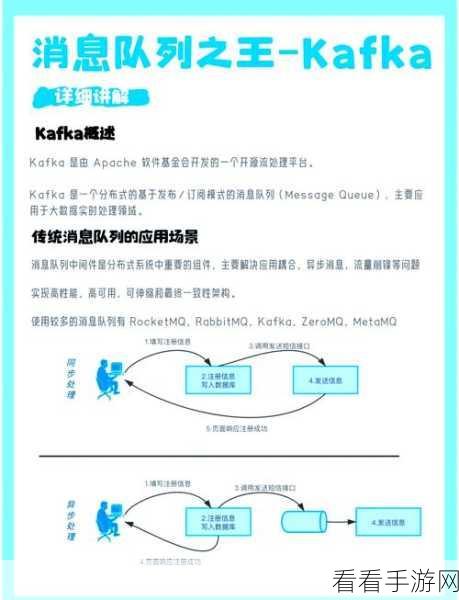
要理解 Kafka 幂等性在跨分区场景下的支持情况,首先需要明确幂等性的实现原理,它通过为每条消息赋予唯一的标识,并在处理过程中进行校验,从而保证相同消息不会被重复处理,跨分区意味着消息可能在不同的分区之间流动,这给幂等性的保证带来了挑战。
不同的 Kafka 版本和配置也会对幂等性跨分区的支持产生影响,在较新的版本中,可能会有一些改进和优化,以更好地应对跨分区的需求,但在某些旧版本中,可能存在限制和不足。
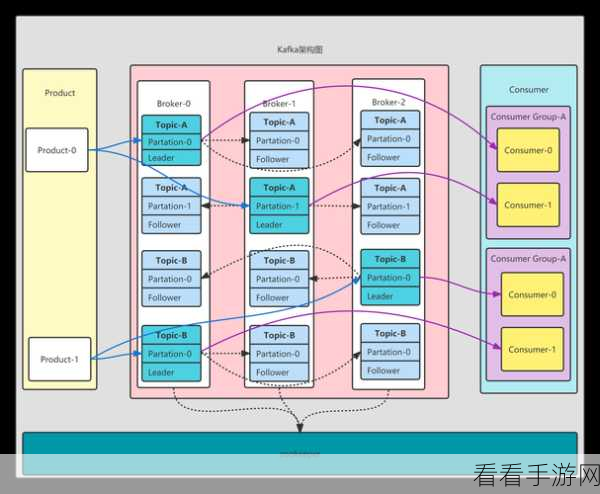
还需要考虑实际业务场景中的数据特点和处理逻辑,如果业务对数据一致性要求极高,那么对 Kafka 幂等性在跨分区场景下的支持情况就需要进行严格的测试和评估。
Kafka 幂等性是否支持跨分区并非一个简单的是或否的问题,而是需要综合考虑多个因素,包括版本、配置、业务需求等,只有深入了解和研究,才能在实际应用中做出合理的决策,充分发挥 Kafka 的优势,确保数据处理的准确性和可靠性。
文章参考来源:Kafka 官方文档及相关技术论坛。
