深度解析,Spark SortBy 并行排序的奥秘与应用
Spark 作为大数据处理领域的强大工具,其 SortBy 操作是否支持并行排序一直是开发者们关注的焦点,在实际应用中,了解这一特性对于优化数据处理流程和提升系统性能至关重要。
Spark 的 SortBy 操作在很多场景中发挥着关键作用,它可以根据指定的字段对数据进行排序,使得数据更加有序和易于处理,对于并行排序的支持情况,需要从多个方面进行深入探讨。
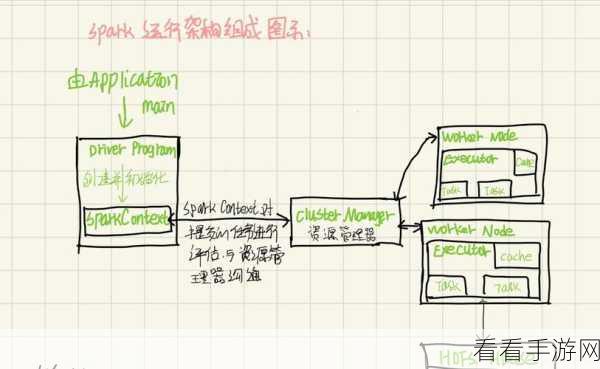
要理解 Spark SortBy 的并行排序,首先要明确其工作原理,SortBy 操作通过将数据分割成多个分区,并在每个分区内进行局部排序,然后对分区进行合并和全局排序,从而实现最终的排序结果,在这个过程中,如果能够充分利用多核处理器和分布式计算资源,就有可能实现并行排序,提高排序的效率。
影响 Spark SortBy 并行排序效果的因素众多,数据的规模和分布是其中的重要因素之一,如果数据量过大且分布不均匀,可能会导致某些分区的处理时间过长,影响并行排序的效果,系统的硬件配置、网络带宽以及 Spark 集群的配置参数等也会对并行排序产生影响。
为了充分发挥 Spark SortBy 的并行排序能力,开发者可以采取一些优化策略,合理设置分区数量是关键之一,根据数据的特点和硬件资源,选择合适的分区数量,能够确保每个分区的工作量相对均衡,提高并行处理的效率,对数据进行预处理,如去除重复数据、过滤无效数据等,可以减少排序的数据量,提升排序速度。
在实际应用中,还可以结合其他 Spark 操作和技术来进一步优化排序过程,使用缓存机制将经常使用的数据缓存到内存中,减少数据的读取时间;利用广播变量共享一些小数据,避免重复计算等。
深入了解 Spark SortBy 是否支持并行排序以及如何优化其性能,对于提升大数据处理的效率和质量具有重要意义,开发者需要根据具体的业务需求和系统环境,灵活运用各种技术和策略,充分发挥 Spark 的强大功能。
参考来源:Spark 官方文档及相关技术论坛。
